구성
- helm 으로 설치한 prometheus-operator 의 prometheus와 alertmanager를 사용함
- 신규로 redis용 PrometheusRule object를 생성하고 이를 prometheus와 연동함
- PrometheusRule는 새로 생성되거나 delete 되는 Pod도 자동으로 인식할 수 있게 helm chart 와 Pod에 연동되어야함
- slack api를 webhook으로 사용
prometheusrules 생성
- vi redis-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
annotations:
meta.helm.sh/release-name: kimdubi-test
meta.helm.sh/release-namespace: default
labels:
app: prometheus-operator
app.kubernetes.io/instance: kimdubi-test
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: redis-cluster
helm.sh/chart: redis-cluster-4.3.1
release: monitoring
name: kimdubi-test-redis-cluster
namespace: default
spec:
groups:
- name: redis-cluster
rules:
- alert: RedisDown
annotations:
description: Redis(TM) instance {{$labels.pod}} is down.
summary: Redis(TM) instance {{$labels.pod}} is down
expr: redis_up{service="kimdubi-test-redis-cluster-metrics"} == 0
for: 1s
labels:
severity: error
- alert: RedisMemoryHigh
annotations:
description: Redis(TM) instance {{$labels.pod}} is using {{ $value }} of
its available memory.
summary: Redis(TM) instance {{$labels.pod}} is using too much memory
expr: |
redis_memory_used_bytes{service="kimdubi-test-redis-cluster-metrics"} * 100 / redis_memory_max_bytes{service="kimdubi-test-redis-cluster-metrics"} > 90
for: 2m
labels:
severity: error
- rule 생성
$ kubectl apply -f redis-rule.yaml
alertmanager 연동
- prometheus 설정 확인
$ kubectl get prometheus -n monitoring
NAME VERSION REPLICAS AGE
monitoring-prometheus-oper-prometheus v2.18.2 1 9m55s
$ kubectl describe prometheus monitoring-prometheus-oper-prometheus -n monitoring
.
.
.
Rule Namespace Selector:
Rule Selector:
Match Labels:
App: prometheus-operator
Release: monitoring
.
.
.
=> prometheus 는 Rule Selector 설정을 통해 release: monitoring label 이 달린 PrometheusRule 만 alert 체크를 함
위에서 새로 생성하는 PrometheusRule label에도 release: monitoring 을 달아줘야 정상적으로 체크가 된다
- alertmanager service 수정
$ kubectl edit service/monitoring-prometheus-oper-alertmanager -n monitoring
spec:
clusterIP: 10.254.88.241
externalTrafficPolicy: Cluster
ports:
- name: web
nodePort: 30903
port: 9093
protocol: TCP
targetPort: 9093
selector:
alertmanager: monitoring-prometheus-oper-alertmanager
app: alertmanager
sessionAffinity: None
type: NodePort
=> type : ClusterIP -> NodePort 로 변경, 9093 port를 30903 port 로 매핑시킴
- prometheus service 수정
$ kubectl edit service/monitoring-prometheus-oper-prometheus -n monitoring
spec:
clusterIP: 10.254.41.25
externalTrafficPolicy: Cluster
ports:
- name: web
nodePort: 30900
port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
prometheus: monitoring-prometheus-oper-prometheus
sessionAffinity: None
type: NodePort
=> type : ClusterIP -> NodePort 로 변경, 9090 port를 30900 port 로 매핑시킴
- 수정된 service 확인
$ kubectl get service -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 2m14s
service/monitoring-grafana NodePort 10.254.217.6 <none> 80:31000/TCP 2m19s
service/monitoring-kube-state-metrics ClusterIP 10.254.89.125 <none> 8080/TCP 2m19s
service/monitoring-prometheus-node-exporter ClusterIP 10.254.233.58 <none> 9100/TCP 2m19s
service/monitoring-prometheus-oper-alertmanager NodePort 10.254.165.227 <none> 9093:30903/TCP 2m19s
service/monitoring-prometheus-oper-operator ClusterIP 10.254.239.202 <none> 8080/TCP,443/TCP 2m19s
service/monitoring-prometheus-oper-prometheus NodePort 10.254.41.25 <none> 9090:30900/TCP 2m19s
service/prometheus-operated ClusterIP None <none> 9090/TCP 2m4s
=> grafana, alertmanager, prometheus 를 ClusterIP -> NodePort로 변경하고 외부 port 매핑됨
alert 확인
토클에서 매핑시킨 FIP 와 NodePort를 통해 매핑한 외부포트로 접근 가능함
rule
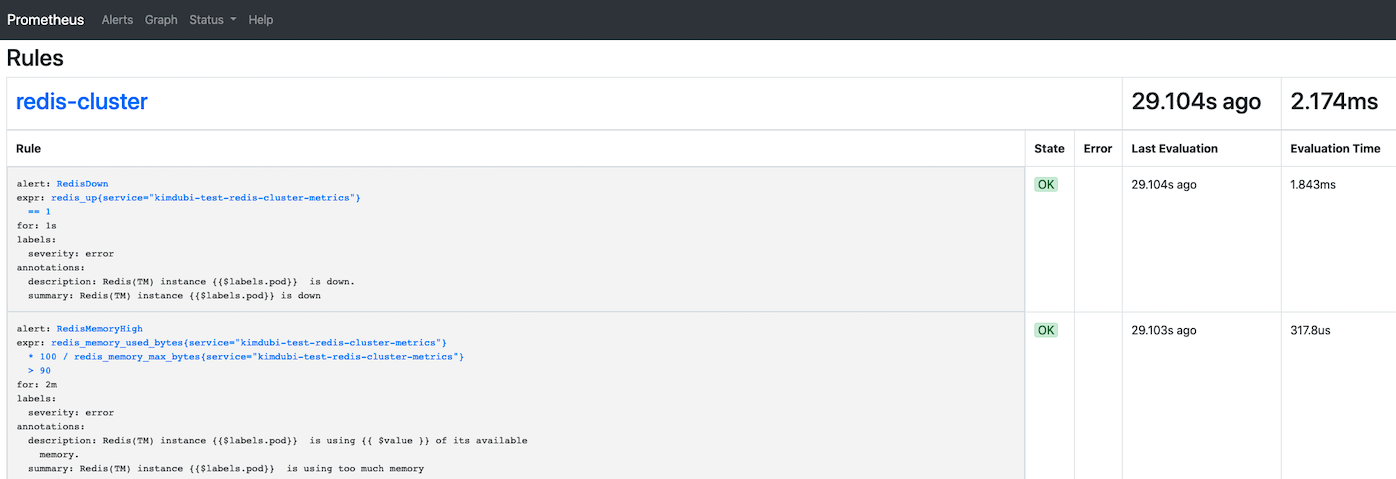
alert
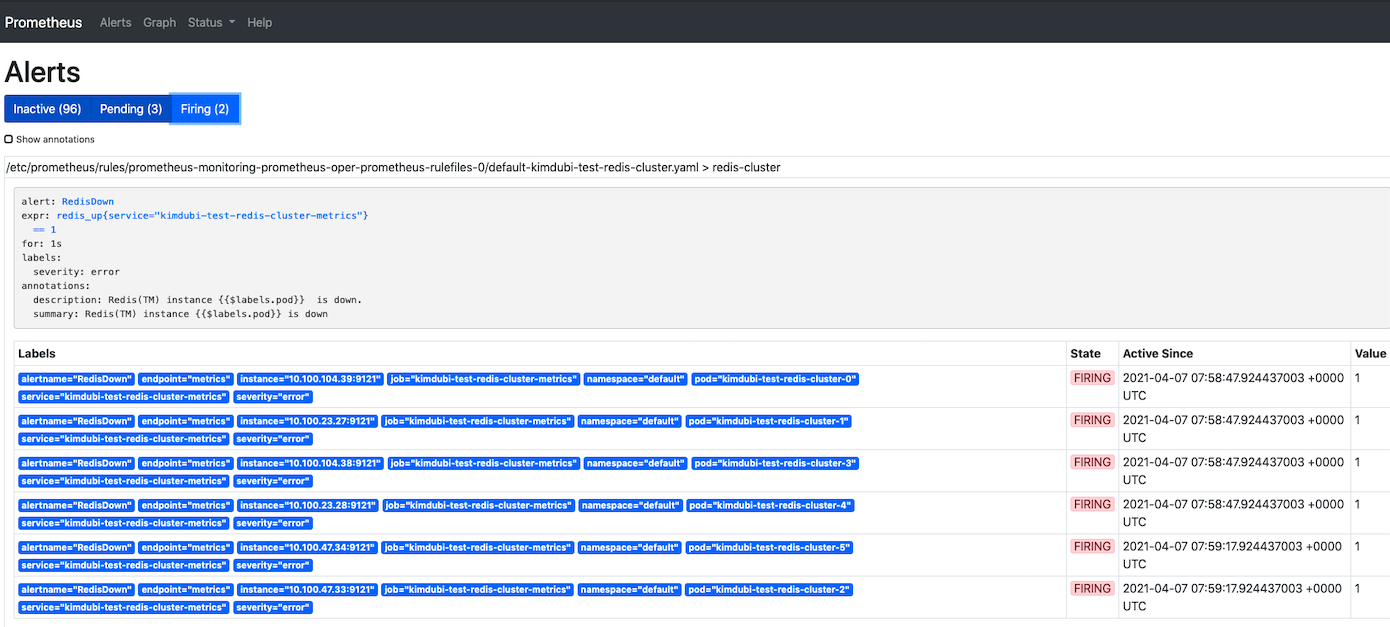
=> alert 체크 되는지 확인을 위해 redis up ==1 로 수정하였음. 잘된다
webhook 연동
- vi prometheus-operator helm 위치 /values.yaml
config:
global:
slack_api_url: 'https://hooks.slack.com/services/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'
route:
receiver: 'redis-team'
group_by: ['alertname']
group_wait: 0s
group_interval: 30s
routes:
- receiver: 'redis-team'
group_wait: 0s
receivers:
- name: 'redis-team'
slack_configs:
- channel: '#kimdubi'
text: '{{ template "custom_title" . }}{{- "\n" -}}{{ template "custom_slack_message" . }}'
templates:
- /alertmanager/template.tmpl
templateFiles:
template.tmpl: |-
{{ define "custom_title" }}
{{- if (eq .Status "firing") -}}
{{- printf "*Triggered: %s (%s)*\n" .CommonAnnotations.triggered .CommonAnnotations.identifier -}}
{{- else if (eq .Status "resolved") -}}
{{- printf "*Recovered: %s (%s)*\n" .CommonAnnotations.resolved .CommonAnnotations.identifier -}}
{{- else -}}
{{- printf "Unknown status repored: %s\n" .CommonAnnotations.triggered -}}
{{- end -}}
{{ end }}
{{ define "custom_slack_message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range .Alerts.Firing -}}
{{- printf "[alerts] : %s\n" .Annotations.summary -}}
{{- end -}}
{{- end -}}
{{ end }}