작성 배경
DynamoDB는 기존 RDBMS에 비해 아래와 같은 장점과 단점이 있는 DBMS로
사용처가 명확하기 때문에 서비스와 DynamoDB가 어울릴지 충분히 검토 후 사용해야 합니다
장점
- 확장성이 훨씬 뛰어나서 트래픽 급증에도 유연하게 대응할 수 있습니다. 트래픽 예측이 안되는 서비스에 강합니다.
- 네트워크 이슈만 없다면 항상 낮은 latency를 보장하기 때문에 OLTP를 안정적으로 잘 처리합니다.
- Key - Value 스토어로 스키마가 유연하고 계층 구조의 데이터를 잘 처리할 수 있습니다.
단점
- 다른 DynamoDB 간 JOIN이 불가능합니다.
- 때문에 하나의 Single Table Design 설계가 굉장히 중요하며 설계가 어렵거나 불가능한 서비스라면 DynamoDB가 적합하지 않습니다.
- OLAP에는 적합하지 않습니다.
- DynamoDB의 데이터를 OLAP에 사용하려면 DynamoDB Streams 같은 CDC기능을 통해 OLAP용도의 다른 DB(ES,Redshift..)에 저장해서 사용해야 합니다.
정리하면
- 트래픽 변동에 따라 자동으로 유연하게 대응이 필요하고
- Key-Value 포맷의 schema-less 데이터를 Single Table 모델링으로 잘 다룰 수 있는 OLTP 서비스
라면 DynamoDB를 효율적으로 사용하실 수 있습니다
Partition Key, Sort Key, Primary Key
Dynamodb에는 세가지 Key 개념이 있습니다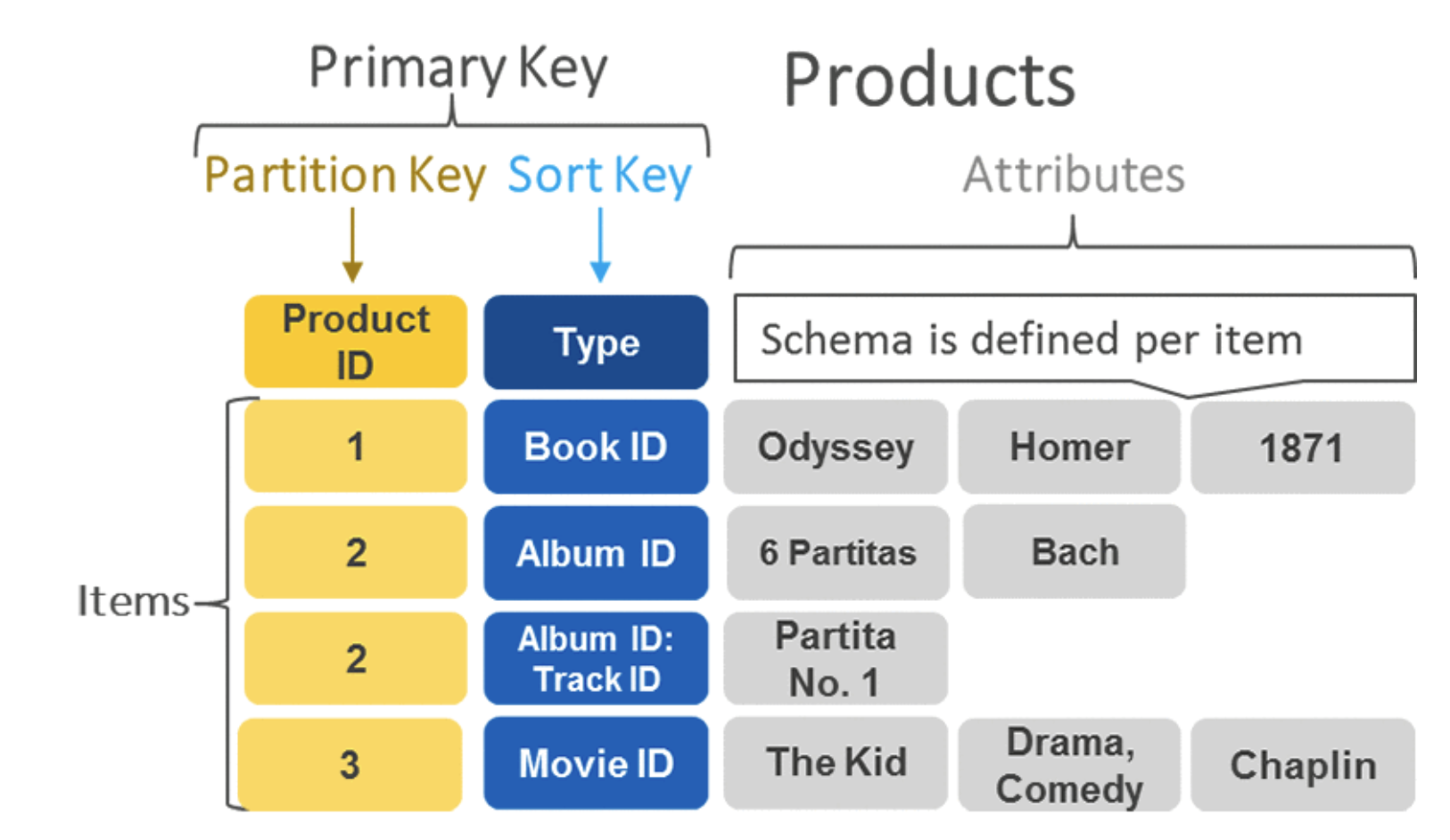
Partition key(필수)
- ddb의 item이 물리적으로 저장되는 partition을 결정하는 Key.
- 하나의 partition에 몰리지 않도록 분산이 잘되는 partition key를 설정하는 것이 중요 합니다.
- Partition Key로 조회할 땐 equal('=') 조건으로만 조회가 가능하며 < >등 범위 조건 조회는 지원하지 않습니다.
sort key(optional)
- sort key를 통해 특정 파티션 키에 대해서 데이터를 정렬 순서로 유지할 수 있습니다.
- 범위를 기반으로 파티션에서 데이터의 일부만 읽어야 하는 액세스 패턴이 있는 경우 정렬 키를 정의하는 것이 좋습니다.
- dynamodb에서 1:n, m:n 관계로 모델링을 확장할 수 있고 <, > 같은 범위 조회와 SQL의 % 조회 (begins_with, contains 등) 를 할 수 있는 유일한 방법이지만, sort key 조건 단독으로 조회는 불가하기 때문에 partition key와 같이 사용되어야합니다.
Primary Key
- DDB 내에서 unique 함을 보장하는 Key로 RDBMS의 PRIMARY KEY, UNIQUE KEY와 동일한 개념입니다.
- Partition Key 단독으로 있을 땐 Partition Key가 Primary Key 역할을 하게 되고
- Partition Key + Sort Key 일 땐 두 Key가 composite Primary Key 역할을 하게 됩니다.
파티션 키는 반드시 분산이 가능한 키로 설계해야 합니다
user_id,email id , invoice number 등 서비스에서 유일한 값이거나, 균일한 비율로 무작위로 요청되는 속성, 중복값이 적은 성격으로 설계해야합니다.
- customerid#productid#countrycode 처럼 여러 attribute를 #로 하나의 Key 값으로 연결하여 partition key로 설정하는 것도 가능합니다
Partition Key로 date 같은 값을 설정하는 것 만큼은 반드시 피해주세요
- ex) ‘20231004’ 같은 date값을 partition Key로 설정하면 많은 데이터가 하나의 파티션으로 들어가기 때문에 RCU, WCU limit에 따른 hot partition 이슈에 취약하며 많은 장애 사례가 있습니다.
- user_id, email_id 같은 값을 partition key로 설정하고 date 같은 값은 Sort Key로 설정할 수 있습니다 . 확장성과 시간으로 범위 조회 모두 문제가 없는 설계입니다
- 반드시 위와 같은 Key를 잡아야한다면 20231004#random_key[0-5] 처럼 뒤에 random key, hash key 를 붙여서 분산할 수 있습니다. (쓰기 샤딩 이라고도 함 )
- Key#RandomKey 예시

몇개의 난수로 나눌지 검토한 뒤에 (트래픽 * 아이템사이즈 ) / 파티션 당 최대 WCU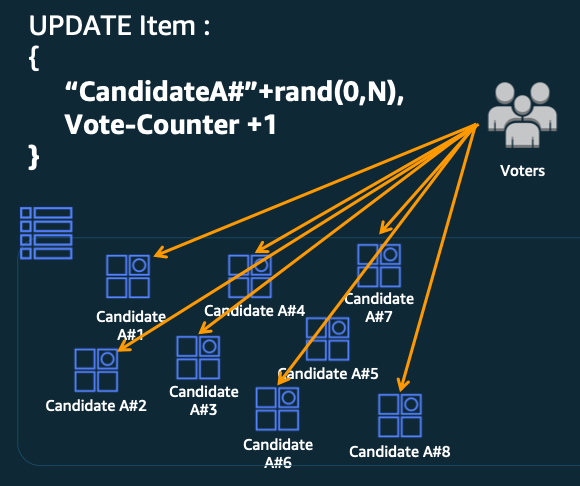
PartitionKey#rand(0,N) 으로 분할하여 저장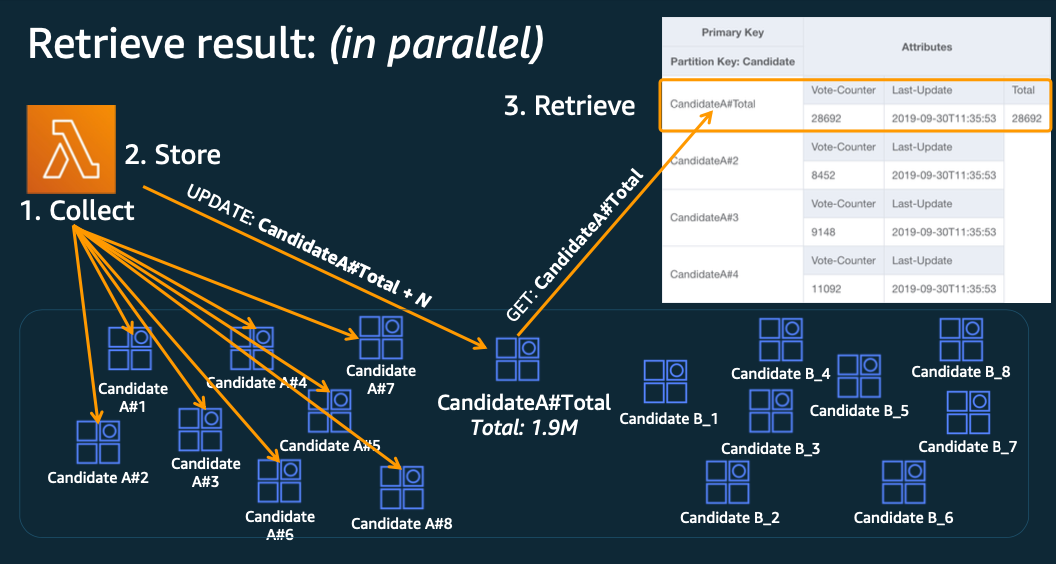
분할한 데이터를 읽어와 통합해주거나 뒷단에서 DynamoDB Streams 같은 CDC를 통해 데이터를 처리하여 통합된 결과를 보여준다
RDBMS처럼 auto increment, uuid를 사용할 순 있지만 ddb에선 안티패턴입니다.
- 이 값들은 보통 서비스에선 의미 없는 값이기 때문에 scan 이나 GSI 등으로 값을 얻은 뒤 재검색하게 되는 비효율이 있습니다.
- 즉, 파티션 키를 통해서 빠르게 데이터를 조회할 수 있는 기회를 날리게 되고, 이를 해결하기 위해 GSI를 추가로 생성하게 되는 낭비가 발생하게 됩니다.
DynamoDB 모델링의 핵심은 Single Table Design 입니다
- 사용전 DynamoDB의 데이터 접근 패턴을 정의하고 위 개념을 바탕으로 Partition Key, Sort Key를 설계해주세요
Query / Scan
두 기능 모두 DDB의 item을 가져오기 위한 API지만 사용방법과 그 목적이 다릅니다.
중요한 것은 Admin이 아닌 User에 의해서 호출되는 API가 Scan 을 사용하는 것 만큼은 반드시 피해주셔야 합니다!
Query
- Partition Key 혹은 Partition Key + Sort Key(Primary key) 를 기반으로 Item을 조회할 때 사용합니다
- GetItem, BatchGetItem 이 해당되며
- RDB 등에서 인덱스를 잘 타는 쿼리처럼 필요한만큼만 데이터를 읽기 때문에 안정적인 성능을 제공합니다.
Scan
Parition Key가 없는 쿼리로 전체 DDB를 풀스캔 하기 때문에 주로 배치작업에서 많이 사용됩니다.
FilterExpression 같은 조건이나 Sort Key를 사용해도 해당 옵션은 전체 풀스캔한 결과에 대해 필터링하거나 정렬을 할 뿐 Scan은 내부적으로 DDB의 모든 Item을 찾습니다
RDB 등에서 인덱스가 없는 풀스캔 쿼리처럼 모든 Item을 찾기 때문에 RCU 소모가 심하고 굉장히 오래걸릴 수 있습니다.
아래처럼 배치작업에서 주로 사용되며 RDB에서 limit offset, PK 페이징 처럼 DDB에서도 페이징을 사용할 수 있습니다 가져와야하는 데이터가 1MB이상으로 크다면 필수입니다
Scan 배치 예시
var request = new ScanRequest
{
TableName = "tb_test",
Limit = pageSize
};
var items = new List<Document>();
do
{
var response = await client.ScanAsync(request);
/// 현재 페이지를 처리합니다
items.AddRange(response.Items);
/// 검색할 item이 더 있는지 확인
if (response.LastEvaluatedKey != null && response.LastEvaluatedKey.Count > 0)
{
/// 다음 페이지의 전용 시작 키 설정, limit offset 혹은 PK 페이징과 같은 부분
request.ExclusiveStartKey = response.LastEvaluatedKey;
}
else
{
/// 더 이상 item이 없으면 루프 종료
request.ExclusiveStartKey = null;
}
} while (request.ExclusiveStartKey != null);
=> 다음 페이지 탐색의 시작점으로 LastEvaluatedKey를 return 하고 ExclusiveStartKey 로 설정하는 구조
정리하면
- User에 의해서 호출되는 API가 Scan을 사용하는 것은 반드시 피해야 합니다.
- Scan은 되도록 배치작업에서만 사용하고 RDB와 마찬가지로 페이징으로 가져올 수 있습니다.
- 가능하면 Scan보다는 Query를 사용해야하며, GSI (원본 테이블과 다른 Partition Key로 재설계) 를 만들어서 해결할 순 없을지 검토해보는 것이 좋습니다
Partition
DynamoDB의 item(데이터)은 결국 모두 Partition에 물리적으로 분산되어 저장됩니다
Hash Sharding 처럼 Partition Key에 해시 함수를 적용하고 그 값에 따라 여러 Partition에 분산 저장 되는 구조입니다.
파티션 수를 계산하는 방법
- 용량 기준일 때 = (RCUs Total/3000) + (WCUs Total/1000)
- 데이터 사이즈 기준일 때 = (총 크기/10GB)
- 파티션 개수 = ceil(max(파티션 수 (용량 기준) , 파티션 단위 (크기별) ))
- 즉, 용량 기준, 데이터 사이즈 기준 중 더 큰 값으로 파티션 개수가 정해집니다.
그리고 WCU와 RCU는 파티션 전체에 고르게 분포되게 됩니다.
ex) WCU , RCU가 각각 1000개 파티션은 10개라면 각각의 파티션에 WCU , RCU가 100개씩 할당되는 구조
Adaptive Capacity라는,
트래픽에 따라 다른 파티션에 할당된 자원을 유동적으로 땡겨오는 내부 기능이 있어서 상황에 따라 조금씩 다를 순 있으나 기본 원리는 위와 같습니다.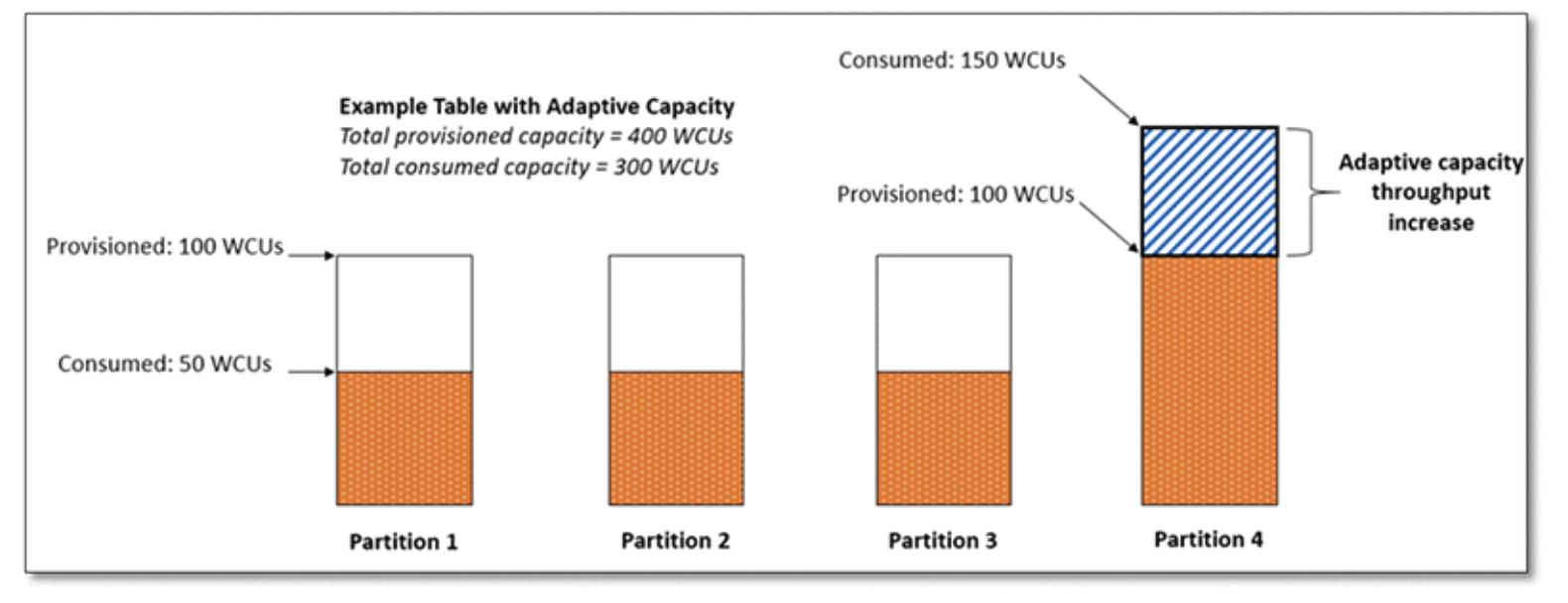
중요한 건 DDB는 할당된 WCU, RCU보다 더 많은 트래픽을 받을 수 없는 구조이기 때문에
그 이상의 트래픽이 들어오면 모두 throttling이 걸리게되고 재시도하게 되어 어플리케이션의 latency가 급증하여 장애로 이어질 수 있습니다.
(버스팅 개념이 있지만 버스팅을 염두하고 설계하는 것은 위험한 패턴입니다)
WCU / RCU
WCU
- WCU (쓰기 용량 단위) 하나는 최대 1KB 항목의 초당 쓰기 한번을 의미 합니다.
- item 1KB보다 크면 더 많은 WCU가 사용됩니다 (1KB 씩 올림 처리)
- 예시
item 크기가 2KB, 초당 12개씩 Write 하면
- => 12 * (2KB/1KB) = 24WCUs
item 크기가 4.5KB인 초당 10개씩 write 하면
- => 10 * (5KB/1KB) = 50WCUs
item 크기가 2KB인 분당 120개씩 write 하면
- => (120/60) * (2KB/1KB) = 4WCUs
RCU
- RCU(읽기 용량 단위) 하나는
- 4KB 크기의 항목에 대해서 초당 강력한 일관된 읽기 1개 (strong consistency)
- 4KB 크기의 항목에 대해서 초당 최종적 일관된 읽기 2개 (Eventually Consistent Read)
- item이 4KB보다 크면 더 많은 RCU가 사용됩니다 (4KB 씩 올림 처리)
읽기 일관성
최종적 일관된 읽기 (Eventually Consistent Read)
- DDB의 default 읽기 설정입니다
- DDB 테이블에서 데이터를 읽을 때, 응답에 최근 완료된 쓰기 작업의 결과가 반영되지 않을 수 있습니다
- 쓰기 작업을 하고 잠시 후 읽기 요청을 반복하면 응답이 최신 데이터를 반환합니다
- RDBMS에서 어느정도 replica lag에 유연하여 Replica로 읽기 분산할 수 있는 유형의 쿼리가 해당합니다.
강력한 일관된 읽기 (Strongly Consistent Read)
DDB는 항상 최신 버전의 데이터를 읽습니다
당연히 최종적 일관된 읽기 보다 latency가 길고 네트워크 이슈에 취약합니다.
RDBMS에서 Replica로 읽기 분산을 하지 못하는 쿼리들, Primary에서 쓰기 후 바로 읽어가는 경우와 동일합니다.
GSI에서는 지원되지 않습니다
최종적 일관된 읽기 보다 2배의 RCU를 소모합니다
예시
- item 크기가 4KB인 12개의 강력한 일관된 읽기
- 12 * (4KB/4KB) = 12RCUs
- item 크기가 8KB인 16개의 최종적 일관된 읽기
- (16/2) * (8KB/4KB) = 16RCUs
- item 크기가 6KB인 12개의 강력한 일관된 읽기
- 12 * (8KB/4KB) = 24RCUs
- item 크기가 4KB인 12개의 강력한 일관된 읽기
Capacity mode
provisioned는 트래픽이 예측가능하고 안정화된 서비스에서 auto-scale 설정과 함께 사용 가능합니다
최초 생성시엔 on-demand로 생성하지만, 일정기간 개발팀과 트래픽 모니터링을 거친 뒤 안정화가 되었다고 판단되면 Provisioned+autoscailing 모드로 전환하는 것도 좋은 방법입니다
on-demand는 provisioned와 달리 min / max 리밋의 설정은 없이 요청하는 대로 트래픽을 모두 받아줍니다
단, on-demand mode여도 Throttling, Hot Partition 이슈로 자유로운 것은 아닙니다.
전체 테이블이 받을 수 있는 트래픽은 제한이 없지만
한 파티션당 최대 RCU / WCU 는 3,000, 1,000개의 조합으로 이루어지기 때문에
파티션키가 잘못 설계된 경우 마찬가지로 hot partition 이슈가 발생할 수 있습니다
on-demand
- 워크로드에 따라 자동으로 읽기/쓰기 확장/축소. 단, 이전 트래픽의 2배이상이 갑자기 들어오는 경우 Throttling이 발생할 수 있기 때문에 Pre warming 작업이 필요할 수 있습니다.
- 최초 생성 시엔 4,000 WCU / 12,000 RCU를 수용할 수 있습니다
- 사용량에 대한 비용 지불, provisioned mode 보다 2.5배 더 비싸기 때문에 트래픽이 안정화된 서비스에서는 provisioned 모드로 전환하여 비용을 절감할 수 있습니다
- on-demand mode가 무제한으로 트래픽을 받는다는 의미는 아닙니다 하나의 파티션이 최대 3,000 / 1,000 만큼의 RCU,WCU를 사용할 수 있는 Limit은 동일하기 떄문에 hot partition 이슈를 염두해야 합니다
provisioned
- 사전에 용량 (초당 읽기/쓰기 수 RCU, WCU)를 운영자가 직접 설정합니다.
- 프로비저닝된 읽기 및 쓰기 용량 단위에 대해 비용 지불합니다
- provisioned mode여도 Auto Scalining 설정이 가능하여 할당된 WCU & RCU의 일정 수치를 사용하면 자동으로 확장되게 할 수 있습니다. (threshold 및 확장 정도도 설정 가능합니다)
Pre warming
- 워크로드에 따라 자동으로 읽기/쓰기 확장/축소. 단, 이전 트래픽의 2배이상이 갑자기 들어오는 경우 Throttling이 발생할 수 있습니다.
- 최초 생성 시엔 4,000 WCU / 12,000 RCU를 수용할 수 있습니다
위에서 살펴본 on-demand capacity mode의 제약사항 때문에
on-demand 모드로 DDB를 생성한 직후, 혹은 적은 트래픽으로 운영하다가 대량 트래픽을 받게 되면 아래처럼 허용된 수용치 이상의 트래픽은 모두 Throttle 걸립니다.
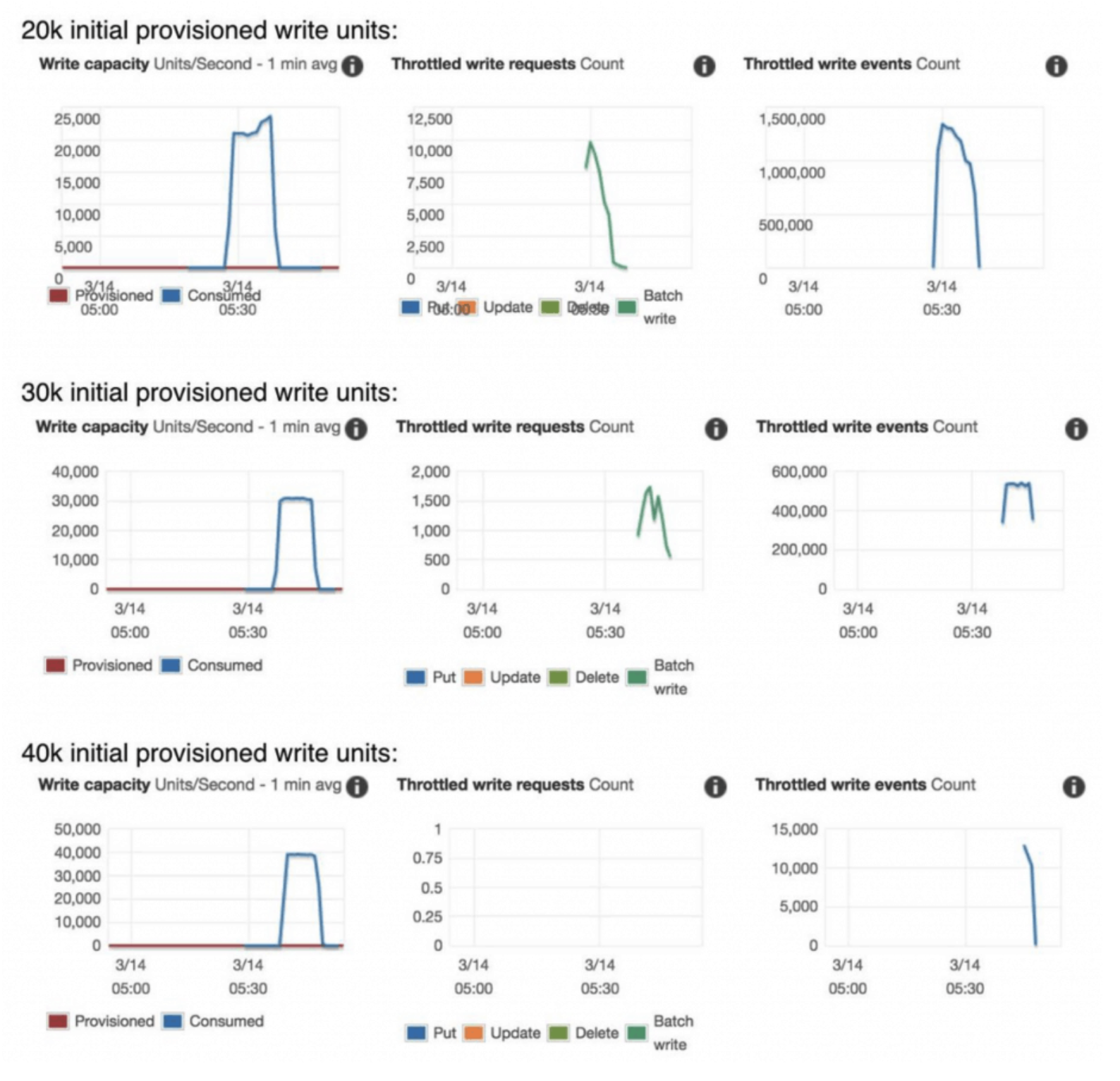
따라서 특별한 이벤트 (선착순,블랙프라이데이 등등) 를 앞두어 트래픽 급증이 예상된다면 반드시 사용중인 DDB의 이전 트래픽 (WCU,RCU)를 확인하여 pre warming을 해야 합니다.
pre warming 방법엔 크게 두가지가 있습니다.
트래픽을 받지 않는 상태에서 이벤트로 곧 20,000 WCU, RCU를 수용해야한다고 가정한다면
- 최초 생성 시 (이벤트를 위해 신규 DynamoDB를 생성한 경우)
- on-demand 의 최초 capacity는 4,000 WCU / 12,000 RCU 이기 때문에 바로 트래픽을 받으면 Throtlling이 발생합니다.
- Provisioned 모드로 10,000 WCU, RCU 를 미리 할당하여 생성한 뒤, on-demand 모드로 바로 변경해줍니다.
- on-demand에서는 직전 트래픽 (할당된 WCU,RCU) 의 2배 까지는 바로 수용할 수 있기 때문에 20,000 WCU, RCU 를 수용할 수 있는 on-demand DDB로 세팅이 완료되었습니다.
- 이미 운영 중인 상태일 때
- 이벤트 전까지 더미 데이터로 목표 트래픽의 부하를 주어 천천히 WCU,RCU를 늘리는 방법도 있지만 시간이 오래걸립니다.
- 따라서 예상되는 트래픽인 20,000 WCU, RCU 의 Provisioned 모드로 변경한 뒤 auto-scailing 모드를 설정해줍니다.
- 그 후 다시 on-demand로의 변경은 24시간마다 한번만 허용되기 때문에, 24시간 이후에 on-demand로 변경해주면 최소 40,000 WCU, RCU를 즉시 받아줄 수 있는 capacity를 가지게 됩니다.
정리하면
- 최초 생성시 : Provisioned 모드로 예상되는 트래픽만큼의 WCU/RCU를 할당하여 생성한 뒤 바로 on-demand로 변경해줌
- 이미 운영중인 상태 : on-demand → Provisioned 모드+auto-scailing 변경 → 24시간 이후 ondemand로 변경 (시간 여유가 없을땐 Provisioned 모드로 유지해도 됩니다)
GSI / LSI
GSI (Global Secondary Index)
- 기존 원본 DDB와 다른 별도의 attribute로 Partition Key, Sort Key를 재설계할 수 있습니다.
- 운영중에 기존 원본 DDB 테이블을 대상으로 추가/삭제가 가능하지만 write가 많은 ddb의 경우엔 피크시간을 피해야합니다.
- 인덱스 생성시 원본 DDB → GSI로 write가 발생하며, 원본 DDB의 write가 너무 많아 GSI의 WCU가 부족하면 원본 DDB의 write throttling을 통해 조절하게 됩니다. (OnlineIndexThrottleEvents 발생)
- 따라서 피크시간을 피하거나, GSI의 write capacity 를 미리 높게 할당해두는 것이 좋습니다.
- Eventual consistent read 만 가능하며 strong consistent read는 불가합니다
- 기존 원본 DDB를 복사한 뒤 GSI를 재설정하는 개념이기 때문에 원본 DDB와 별도의 읽기/쓰기 용량(RCU/WCU) 할당됩니다
- 원본 DDB 테이블의 capacity는 충분한데 GSI capacity 가 부족하여 throttling이 걸릴 수 있습니다
LSI (Local Secondary Index)
- DDB 테이블을 생성할 때만 설정할 수 있으며 운영 중 추가/삭제가 불가능합니다. (테이블당 5개)
- 원본 테이블과 동일한 Partition Key를 사용하고, 테이블에 할당된 WCU / RCU를 사용합니다.
- Eventual, strong consistency 모두 사용이 가능합니다.
GSI 사용 예시
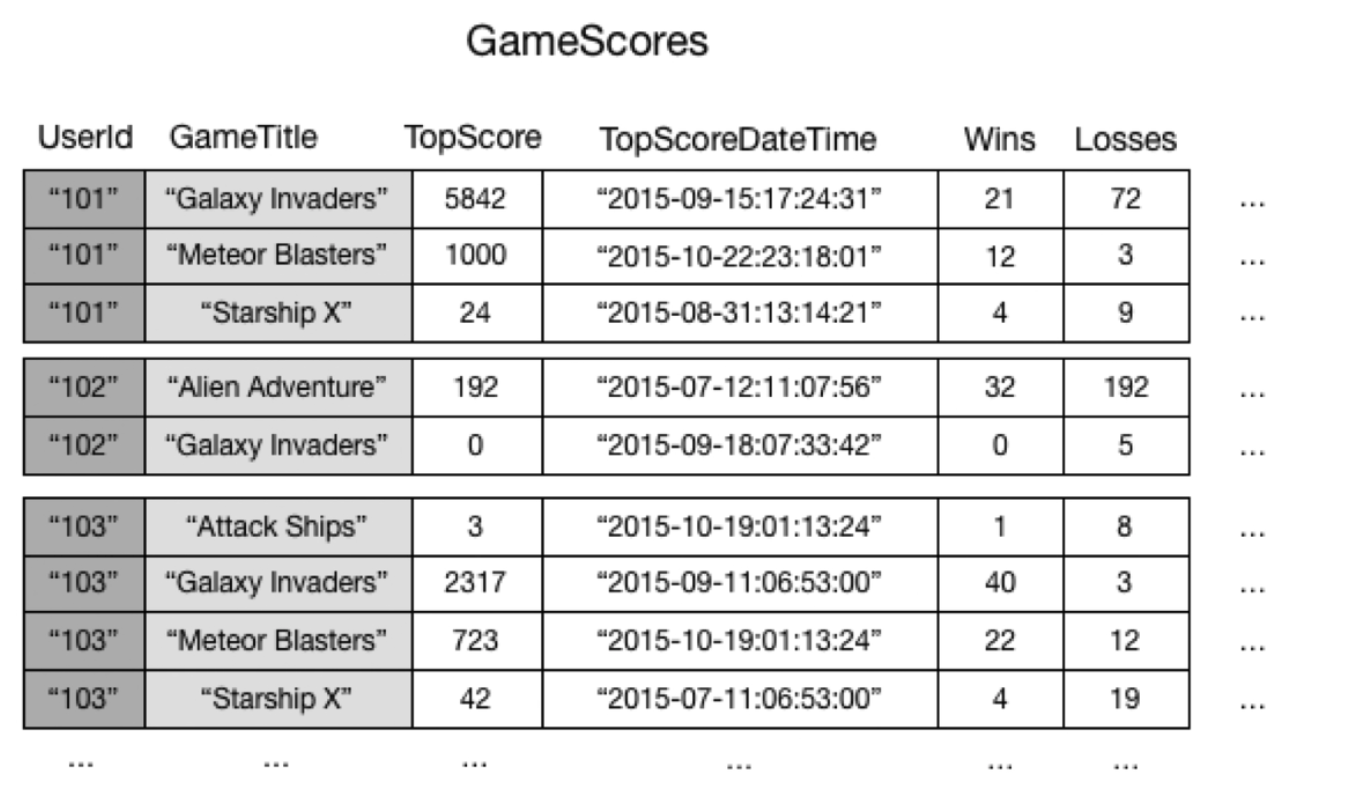
GameScores 테이블에서 Partition Key는 UserId, Sort Key는 GameTitle입니다.
각 user를 기준으로 데이터를 보기는 쉽지만 각 게임에서 TopScore ranker를 찾고싶다면
모든 데이터에 대해서 scan해야 하기 때문에 시간도 오래 걸리고 RCU 소모가 심할 수 있습니다
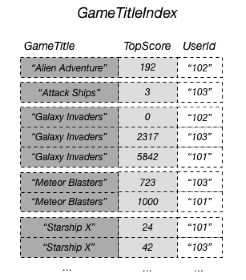
GSI 는 원본 DDB와는 다른 attribute로 PartitionKey, SortKey를 설정할 수 있기 때문에
GameTitle, TopScore로 Partition Key, Sort Key로 GSI를 생성하면
각 게임 별 탑 랭커와 점수를 쉽게 확인할 수 있습니다.
DDB도 ScanIndexForward 기능 등을 통해 SortKey로 정렬 방향을 설정할 수 있습니다
TTL
- Redis, MongoDB의 TTL과 동일한 개념으로 아이템 별 데이터의 유효기간 설정이 가능하며, 유효기간이 지난 데이터는 자동 삭제됩니다.
- DDB에 TTL로 사용할 attribute를 지정하고 item을 write할 때 해당 attribute에 이 item이 만료될 시간을 unix epoch time으로 기록합니다.
- ex) TTL attribute 에 1697180094 을 설정하면 이 item은 2023년 10월 13일 금요일 오후 3:54:54 GMT+09:00에 삭제됩니다
- DDB 테이블 생성시 TTL을 설정하지 않는 경우 무한정 수십TB 까지도 커지는 경우가 있어서 데이터가 계속 증가하는 성격의 DDB라면 TTL을 반드시 설정해주어야 합니다.
작동 방식
- DeleteItem 작업과 동일한 방식으로 GSI, LSI 에서 제거 (추가 비용없이 처리)
- 100% 백그라운드에서 진행되며 성능에 전혀 영향이 없음
- Dyanmo Streams 을 통해 삭제시 별도 저장 및 처리 가능

GZIP 등 압축으로 성능 개선하기
DDB는 item의 크기에 굉장히 민감한 서비스입니다.
하나의 Item은 최대 400KB라는 제약 뿐만 아니라 WCU, RCU 등 많은 것들이 item의 크기에 영향을 받습니다.
때문에 대용량의 attribute를 저장할 땐 gzip 같은 압축을 통해 데이터의 사이즈를 줄이는 것도 성능 개선에 큰 효과가 있습니다.
기존에 Redis 등에서 적용한 것과 같이 gzip을 사용했을 때의 예시입니다
const { loremIpsum } = require('lorem-ipsum');
const { gzipSync } = require('zlib');
const content = loremIpsum({
count: 20,
units: "paragraph",
format: "plain",
paragraphLowerBound: 5,
paragraphUpperBound: 15,
sentenceLowerBound: 5,
sentenceUpperBound: 15,
suffix: "\n\n\n",
});
const compressed = gzipSync(content);
console.log(`total size (uncompressed): ~${Math.round(content.length/1024)} KB`);
console.log(`total size (compressed): ~${Math.round(compressed.length/1024)} KB`);
Generated a text with 12973 characters and 1943 words
total size (uncompressed): ~13 KB
total size (compressed): ~4 KB
Write capacity for compressed post { TableName: 'tb_test', CapacityUnits: 4 }
Write capacity for raw post { TableName: 'tb_test', CapacityUnits: 14 }
Read capacity for compressed post { TableName: 'tb_test', CapacityUnits: 0.5 }
Read capacity for raw post { TableName: 'tb_test', CapacityUnits: 2 }
=> 압축 전후 데이터 사이즈뿐만 아니라 저장할 때의 WCU,RCU도 크게 차이나는 것을 확인할 수 있습니다