테스트 배경
특정 시간 내에 대량 데이터 적재를 완료해야하는 개발팀,,
그러나 데이터가 너무 많아 시간이 빠듯하였고, 이에 kafka의 파티션을 늘려 parallel 하게 데이터 적재를 함으로써 시간 내에 완료되도록 하였으나
그 영향으로 병렬 쓰레드가 많아지자 DB의 cpu 사용률이 높아지고 DB 스펙업을 요청하게 되었다
요청을 받은 DBA는 비용절감 추세에 따라 가능하면 스펙업 보단 쓰기의 부하를 줄이는 방식을 가이드하였고
로직 개선 등 근본적인 해결방법 외에 우선 DB쪽에서 간단히 파라미터 수정으로 쓰기 부하를 줄이는 방법을 적용하게 되었다.
그리고 이참에 해당 파라미터에 대해 조금 더 자세하게 소스에서 살펴보았다,,,
테스트 결론
- innodb_flush_log_at_trx_commit =1 → 0 으로 수정하는 것 만으로 두배의 성능 개선 효과가 있었다
- 단! 이 설정은 아래 코드에서 볼 수 있듯 redo log를 약 1초 마다 디스크로 내려쓰기 때문에 갑작스런 DB 비정상 종료시엔 약 1초간의 데이터 유실이 발생할 수 있다
- 그렇기 때문에 꼭! 장애시점 근처부터 kafka 토픽에서 데이터를 resync 할 수 있는 서비스, 1초정도의 데이터유실은 감내할 수 있는 서비스에서 사용하도록 한다
시작하기 전에 잠깐 사전지식
MySQL에서 데이터가 변경되면 buffer pool에 데이터를 변경하고, 데이터파일을 변경하는 것 외에도 redo log 라는 것을 따로 기록한다.
redo log는 DB가 비정상적으로 종료되었을 때에도 데이터를 복구하기 위한 즉 데이터의 안정성 뿐만 아니라
데이터 페이지로 변경사항을 바로바로 내려쓰는 게 아니라 버퍼링을 가능하게 하여 DB성능에도 도움을 주는 역할을 한다.
그리고 이 Redo log를 언제 내려쓰냐에 대한 파라미터가 있는데 그것이 바로 innodb_flush_log_at_trx_commit 이다

- 위의 그림에서 알 수 있듯이, 해당 값에 따라 순간적인 장애시 트랜잭션을 잃을 수 있다.
- 0 인 경우, MySQL 이나 OS가 갑자기 crash 된다면 최대 1초동안의 트랜잭션을 잃을 수 있다.
- 1 인 경우, 안전하다.
- 2 인 경우, OS가 갑자기 crash 된다면 최대 1초동안의 트랜잭션을 잃을 수 있다. 하지만 MySQL 장애시에는 이미 OS 영역으로 데이터는 넘어갔기 때문에 안전할 수 있다.
- 각 값에 따라, 엄청난 성능을 보일 수 있다.
- 지난번에 엄청난 양의 log를 위하여 MySQL을 사용하는 팀이 있었는데, 해당값을 1에서 0으로 수정함에 따라 성능이 7배 빨라지기도 했다.
- 최대 1초정도의 트랜잭션은 무시할 수 있는 서비스 혹은 log를 저장할 서버라면 해당값을 1에서 0으로 변경할 수 있다.
- MySQL을 가장 빠르고 쉽게 튜닝할 수 있는 parameter 중의 하나이다.
디버깅
위 그림에서 본 것과 같은 동작을 mysql 소스에서 확인해보자
- 대략적인 과정
innobase_commit()
====>trx_commit_complete_for_mysql()
====>trx_flush_log_if_needed() ====> 쿼리가 DDL이면,,,
====>log_write_up_to()
====>trx_flush_log_if_needed_low() ====> 쿼리가 DML이면,,,
====>log_write_up_to() ====> 이부분에서 innodb_flush_log_at_trx_commit 설정값에 따라 동작방식에 차이가 있음
=> 기본적으로 트랜잭션이 commit 된 이후 수행되는 프로세스임
수행하는 트랜잭션이 DDL이면 Redo log도 바로 내려쓰는 동작이고
DML이면 innodb_flush_log_at_trx_commit 설정값 (0,1,2) 에 따라 Redo log를 내려쓰는 동작이 조금씩 다르다
### 코드 부분
static bool innobase_flush_logs(handlerton *hton, bool binlog_group_flush) {
DBUG_TRACE;
assert(hton == innodb_hton_ptr);
if (srv_read_only_mode) {
return false;
}
/* If !binlog_group_flush, we got invoked by FLUSH LOGS or similar.
Else, we got invoked by binlog group commit during flush stage. */
if (binlog_group_flush && srv_flush_log_at_trx_commit == 0) {
/* innodb_flush_log_at_trx_commit=0
(write and sync once per second).
Do not flush the redo log during binlog group commit. */
/* This could be unsafe if we grouped at least one DDL transaction,
and we removed !trx->ddl_must_flush from condition which is checked
inside trx_commit_complete_for_mysql() when we decide if we could
skip the flush. */
return false;
}
/* Signal and wait for all GTIDs to persist on disk. */
if (!binlog_group_flush) {
auto >id_persistor = clone_sys->get_gtid_persistor();
gtid_persistor.wait_flush(true, true, nullptr);
}
/* Flush the redo log buffer to the redo log file.
Sync it to disc if we are in FLUSH LOGS, or if
innodb_flush_log_at_trx_commit=1
(write and sync at each commit). */
log_buffer_flush_to_disk(!binlog_group_flush ||
srv_flush_log_at_trx_commit == 1);
return false;
}
### 디버깅
5671 log_buffer_flush_to_disk(!binlog_group_flush || srv_flush_log_at_trx_commit == 1);
1738 if (trx->ddl_operation || trx->ddl_must_flush) {
(gdb) p trx->ddl_operation || trx->ddl_must_flush
$1 = false
1742 trx_flush_log_if_needed_low(lsn);
(gdb) p lsn
$2 = 7076920275
=> innodb_flush_log_at_trx_commit 설정값을 확인하고 ( srv_flush_log_at_trx_commit == 1)
쿼리가 DDL인지를 확인한다. DDL이면 redo log를 바로 write & flush 까지 하게 된다
DDL이 아니기 때문에 DML 처리를 위해 trx_flush_log_if_needed_low 로 넘어간다
trx_commit = 1 일 때
### 코드부분
/** If required, flushes the log to disk based on the value of
innodb_flush_log_at_trx_commit. */
static void trx_flush_log_if_needed_low(lsn_t lsn) /*!< in: lsn up to which logs
are to be flushed. */
{
#ifdef _WIN32
bool flush = true;
#else
bool flush = srv_unix_file_flush_method != SRV_UNIX_NOSYNC;
#endif /* _WIN32 */
Wait_stats wait_stats;
switch (srv_flush_log_at_trx_commit) {
case 2:
/* Write the log but do not flush it to disk */
flush = false;
[[fallthrough]];
case 1:
/* Write the log and optionally flush it to disk */
wait_stats = log_write_up_to(*log_sys, lsn, flush);
MONITOR_INC_WAIT_STATS(MONITOR_TRX_ON_LOG_, wait_stats);
return;
case 0:
/* Do nothing */
return;
}
}
### 디버깅
(gdb) p srv_flush_log_at_trx_commit
$4 = 1
1717 wait_stats = log_write_up_to(*log_sys, lsn, flush);
(gdb) p flush
$5 = true
(gdb) info locals
flush = true
wait_stats = {wait_loops = 0}
=> 여기서는 맨 위에서 보았듯 trx_commit이 0,1,2 에 따라 다르게 동작을 처리하는데
현재 이 쿼리는 trx_commit 1로 수행되었으므로
commit 이후 log_write_up_to 을 호출하면서 바로 redo log write & flush 처리를 한번에 해버린다
commit 하면서 Redo log 까지 디스크로 내려쓰기 때문에, DB가 비정상 종료되어도 데이터 유실이 없다.
trx_commit = 0,2 일 때
switch (srv_flush_log_at_trx_commit) {
case 2:
/* Write the log but do not flush it to disk */
flush = false;
[[fallthrough]];
case 1:
/* Write the log and optionally flush it to disk */
wait_stats = log_write_up_to(*log_sys, lsn, flush);
MONITOR_INC_WAIT_STATS(MONITOR_TRX_ON_LOG_, wait_stats);
return;
case 0:
/* Do nothing */
return;
=> 반면 0,2 일 땐 1과 달리 log_write_up_to 를 바로 하지 않는다
또한 0과 2사이에서도 또 미묘한 차이가 있는데
trx_commit = 2일 때는 case 2: 에 속하므로 우선 여기에서 flush = false 를 들고,
다시 case 1의 log_write_up_to 을 또 수행한다.
( [[fallthrough]] 이 코드는 c++에서 의도적으로 다음 case block으로 넘어가도록 하는 기능이라고 한다 )
위에 사전지식 부분에서 본 것 처럼 trx_commit=2는 commit 하면 os cache로 flush 까지는 보장하는 동작을 보여주고 있다
0일 때는 정말 아무것도 안하고 return 한다
Breakpoint 1, innobase_commit (hton=0x1b187830, thd=0xfffe5c010a10, commit_trx=false) at /mysql_source/mysql-8.0.32/storage/innobase/handler/ha_innodb.cc:5753
.
.
.
/* Don't do write + flush right now. For group commit
to work we want to do the flush later. */
trx->flush_log_later = true;
}(gdb)p trx->flush_log_later
$4 = true
(gdb)
=> trx_commit = 0,2 인 경우엔 특별히 flush_log_later , 즉 flush는 나중에 하라고 상태까지 변경해준다
Wait_stats log_write_up_to(log_t &log, lsn_t end_lsn, bool flush_to_disk) {
.
.
.
if (srv_flush_log_at_trx_commit != 1) {
/* We need redo flushed, but because trx != 1, we have
disabled notifications sent from log_writer to log_flusher.
The log_flusher might be sleeping for 1 second, and we need
quick response here. Log_writer avoids waking up log_flusher,
so we must do it ourselves here.
However, before we wake up log_flusher, we must ensure that
log.write_lsn >= lsn. Otherwise log_flusher could flush some
data which was ready for lsn values smaller than end_lsn and
return to sleeping for next 1 second. */
if (log.write_lsn.load() < end_lsn) {
wait_stats += log_wait_for_write(log, end_lsn, &interrupted);
}
}
=> 결국 주석의 내용처럼 log_writer 와 log_flusher 가 일어날때까지 기다려야하고 이것들은 약 1초마다 깨어난다
즉, 위 사전지식 부분의 trx_commit 설명에서 DB down 혹은 OS 서버 down 시 약 1초간 데이터유실이 있다는 내용은
trx_commit이 1이 아니면 이 log_writer, flusher가 동작할때까지 기다려야하는데
이 쓰레드는 1초마다 일어나기 때문에 얘네가 잠들어있는 약 1초동안의 데이터는 유실이 된다는 의미가 된다
그리고 위 과정을 체크해주는 것은 이 master thread의 동작이다
static void srv_master_do_active_tasks(void) {
const auto cur_time = std::chrono::steady_clock::now();
static std::chrono::steady_clock::time_point last_dict_lru_check;
/* First do the tasks that we are suppose to do at each
invocation of this function. */
++srv_main_active_loops;
MONITOR_INC(MONITOR_MASTER_ACTIVE_LOOPS);
/* ALTER TABLE in MySQL requires on Unix that the table handler
can drop tables lazily after there no longer are SELECT
queries to them. */
{
srv_main_thread_op_info = "doing background drop tables";
const auto counter_time = std::chrono::steady_clock::now();
row_drop_tables_for_mysql_in_background();
MONITOR_INC_TIME(MONITOR_SRV_BACKGROUND_DROP_TABLE_MICROSECOND,
counter_time);
}
ut_d(srv_master_do_disabled_loop());
if (srv_shutdown_state.load() >=
SRV_SHUTDOWN_PRE_DD_AND_SYSTEM_TRANSACTIONS) {
return;
}
/* Do an ibuf merge */
{
srv_main_thread_op_info = "doing insert buffer merge";
const auto counter_time = std::chrono::steady_clock::now();
ibuf_merge_in_background(false);
MONITOR_INC_TIME(MONITOR_SRV_IBUF_MERGE_MICROSECOND, counter_time);
}
/* Flush logs if needed */
log_buffer_sync_in_background();
/* Now see if various tasks that are performed at defined
intervals need to be performed. */
if (srv_shutdown_state.load() >=
SRV_SHUTDOWN_PRE_DD_AND_SYSTEM_TRANSACTIONS) {
return;
}
srv_update_cpu_usage();
if (trx_sys->rseg_history_len.load() > 0) {
srv_wake_purge_thread_if_not_active();
}
if (cur_time - last_dict_lru_check > SRV_MASTER_DICT_LRU_INTERVAL) {
last_dict_lru_check = cur_time;
srv_main_thread_op_info = "enforcing dict cache limit";
const auto counter_time = std::chrono::steady_clock::now();
ulint n_evicted = srv_master_evict_from_table_cache(50);
if (n_evicted != 0) {
MONITOR_INC_VALUE(MONITOR_SRV_DICT_LRU_EVICT_COUNT, n_evicted);
}
MONITOR_INC_TIME(MONITOR_SRV_DICT_LRU_MICROSECOND, counter_time);
}
}
=> master thread의 동작 중 하나인 이것은 매 초 마다 DB살림살이에 필요한 각종 작업들을 한다.
buffer pool의 데이터 페이지에 대한 LRU 관리, 인덱스 수정을 위한 change buffer, 각종 모니터링 지표 수집, undo log purge(HLL) 작업 외에도
이번 글의 주인공인 log_buffer_sync_in_background
redo log를 내려쓰는 작업도 같이 진행한다.
성능 테스트 및 적용 사례
- 간단한 성능테스트
- 각각 innodb_flush_log_at_trx_commit =0 , 1 일때 sysbench로 qps를 비교해보았다
- 구간에 따라 trx 0이 1에 비해 거의 두배의 성능 향상 (QPS) 을 보여주었다
| Thread | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|---|---|---|---|
| trx 0 | 799 | 1568 | 3081 | 5565 | 9661 | 16151 | 22201 | 26848 | 30926 | 35790 |
| trx 1 | 1513 | 2991 | 6011 | 12157 | 23148 | 33785 | 40275 | 45640 | 44940 | 45362 |
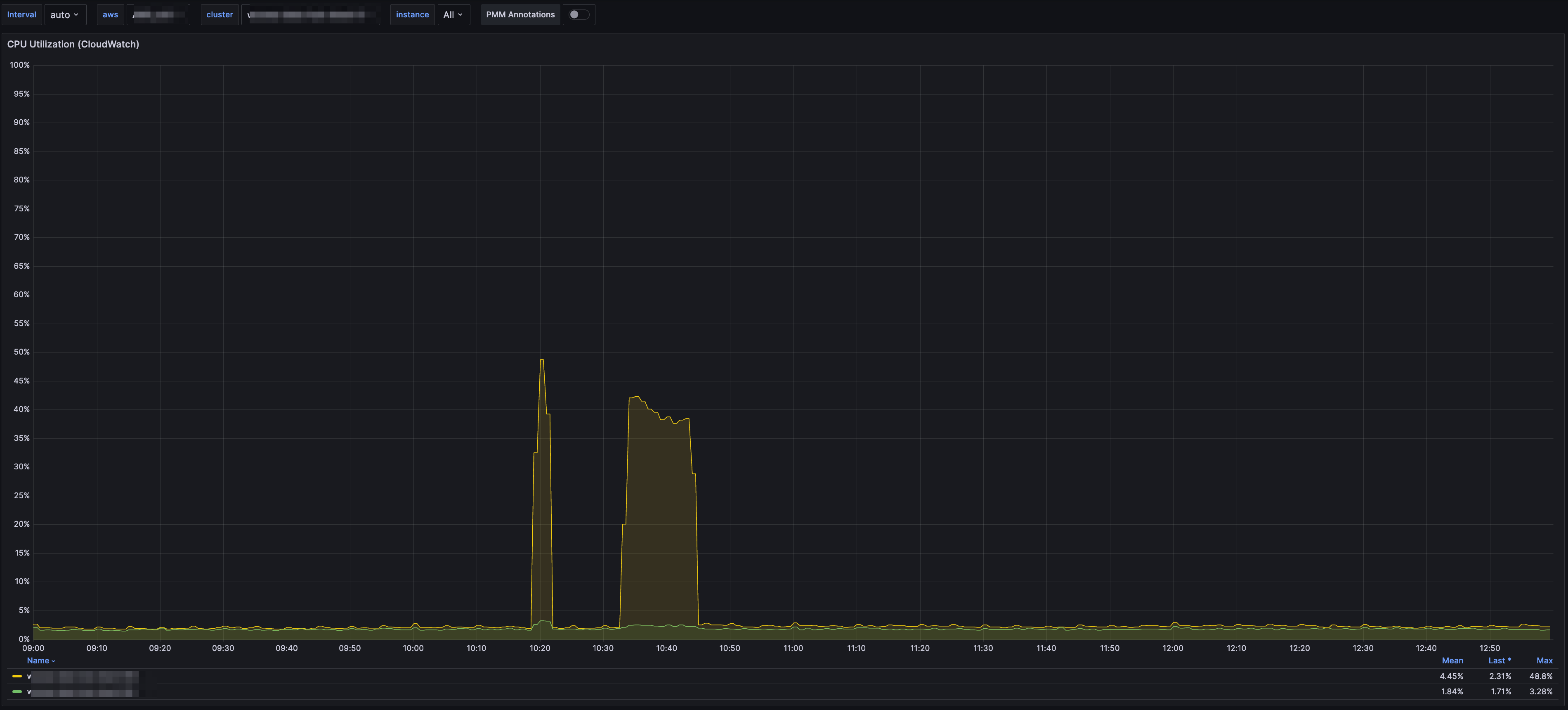
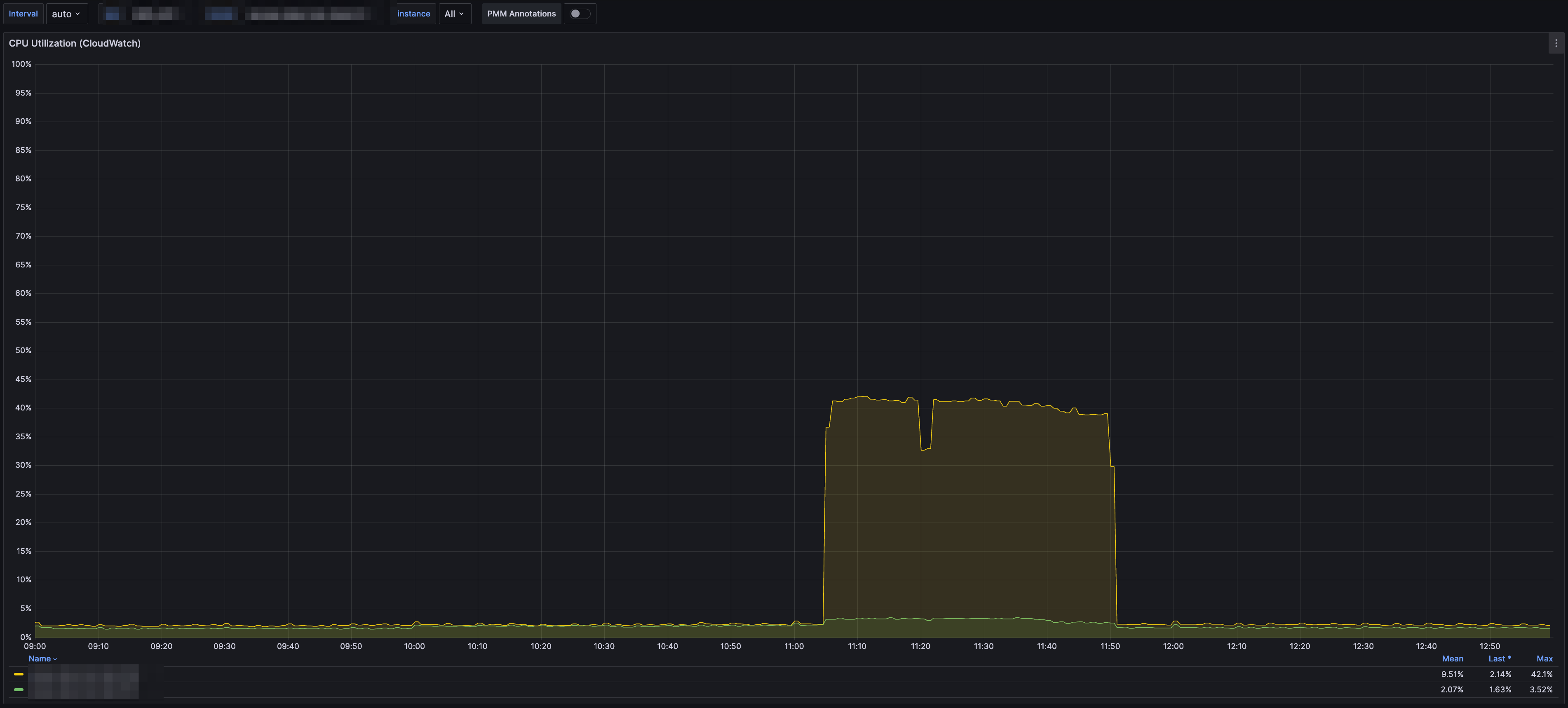
- 서비스 적용 사례
- 같은 양의 데이터를 적재하는데 수행 속도가 두배이상 개선됨
- 데이터 적재하는 시간에 여유가 생겼으므로 카프카쪽 파티션을 줄여서 DB 리소스 부하 현상 개선도 가능한 상황이 되었다
 ====>
====>