MySQL fragmentation 원인과 해결방법
MySQL에서 테이블 fragmentation 현상을 경험해보신 적 있으신가요?
fragmentation이란 insert & delete 가 수차례 반복되면서 page 안에 회수가 안되는 사용되지 않는 부분이 많아지면서 발생하게 되는데
그 영향으로 테이블이 실제로 가져야 하는 OS 공간 보다 더 많은 공간을 차지하게 됩니다.
얼마전에 저도 운영하는 서비스에서 단편화가 심하게 된 테이블을 발견하게 되었는데요
이번 글에서는 단편화현상을 해소하는 방법과 그 원인에 대해서 알아보도록 하겠습니다.
fragmentation 확인
- 대상 테이블 OS 사이즈
$ du -sh tb_test*
12K tb_test.frm
78G tb_test.ibd
- db 내 사이즈 확인
mysql> SELECT table_name,
-> table_rows,
-> round(data_length/(1024*1024),2) as 'DATA_SIZE(MB)',
-> round(index_length/(1024*1024),2) as 'INDEX_SIZE(MB)'
-> FROM information_schema.TABLES
-> WHERE table_schema = 'test'
-> and table_name='tb_test'
-> GROUP BY table_name ;
+------------+------------+---------------+----------------+
| table_name | table_rows | DATA_SIZE(MB) | INDEX_SIZE(MB) |
+------------+------------+---------------+----------------+
| tb_test | 351267 | 22336.02 | 295.39 |
+------------+------------+---------------+----------------+
1 row in set (0.05 sec)
=> OS 서버에서 확인할 땐 78gb지만 db 내에서 조회해봤을 땐 대략 22gb정도 되는 테이블로 확인했습니다
그만큼 fragmentation 됐다는 의미이며 테이블 최적화 작업 진행 시 56gb 정도 회수 가능한 상황입니다
테이블 최적화 방법
- CTAS 로 테이블 재생성
=> 서비스 점검 필수 라서 제외 - optimize table
=> online dml 이 가능하지만 시간이 오래 소요되고 성능에 영향을 끼칠 수 있습니다
실제로 이번에 아래 커맨드로 optimize table을 slave 에서 수행했는데
disk i/o utilization 이 100%을 치면서 replication 반영 속도가 느려지면서 복제지연 문제와
optimize 커맨드가 마지막에 metadata lock을 획득하는데 실패하면서 작업이 실패하게 되었습니다.
set sql_log_bin=0;
### optimize table NO_WRITE_TO_BINLOG 옵션 추가, MMM을 사용하기 때문에 master로 전달되는 것을 방지하기 위함임
optimize NO_WRITE_TO_BINLOG table test.tb_test;
- pt-osc
=> 위와 같은 이유들로 optimize 테이블이 online dml이 가능함에도 pt-osc를 가장 추천합니다
pt-online-schema-change \
--alter "ENGINE=InnoDB" D=optimize_test,t=tb_test \
--drop-old-table \
--no-drop-new-table \
--chunk-size=1000 \
--sleep=0.01 \
--recursion-method=dsn=t=mysql.dsn \
--max-lag=60 \
--defaults-file=/home1/irteam/db/mysql/my.cnf \
--host=testserver \
--port=3306 \
--user=testuser \
--password=test \
--max-load="Threads_running=100" \
--critical-load="Threads_running=200" \
--chunk-index=PRIMARY \
--charset=utf8 \
--set-vars="innodb_lock_wait_timeout=1,lock_wait_timeout=1,binlog_format='statement'" \
--no-check-alter \
--statistics \
--execute
=> engine=innodb 커맨드를 수행하도록 pt-osc를 사용하면 optimize table한 것과 동일한 효과를 볼 수 있습니다
- 작업 결과
$ du -sh tb_test*
12K tb_test.frm
21G tb_test.ibd
fragmentation 원인
아래와 같이 insert 를 수행했을 때 disk에는 어떻게 저장될까요?
다음은 CUBRID라는 RDBMS의 레코드 저장 방식으로 MySQL의 내용은 아니지만 거의 모든 RDBMS가 비슷한 방식이기 때문에 CUBRID의 사례로 살펴보도록 하겠습니다.
INSERT INTO t1(c1) VALUES ('aaa');
INSERT INTO t1(c1) VALUES ('bbbbb');
INSERT INTO t1(c1) VALUES ('cc');
INSERT INTO t1(c1) VALUES ('dddddd');
아주 간단하게 생각하면 아래처럼 순차적으로 저장된다고 생각할 수 있습니다.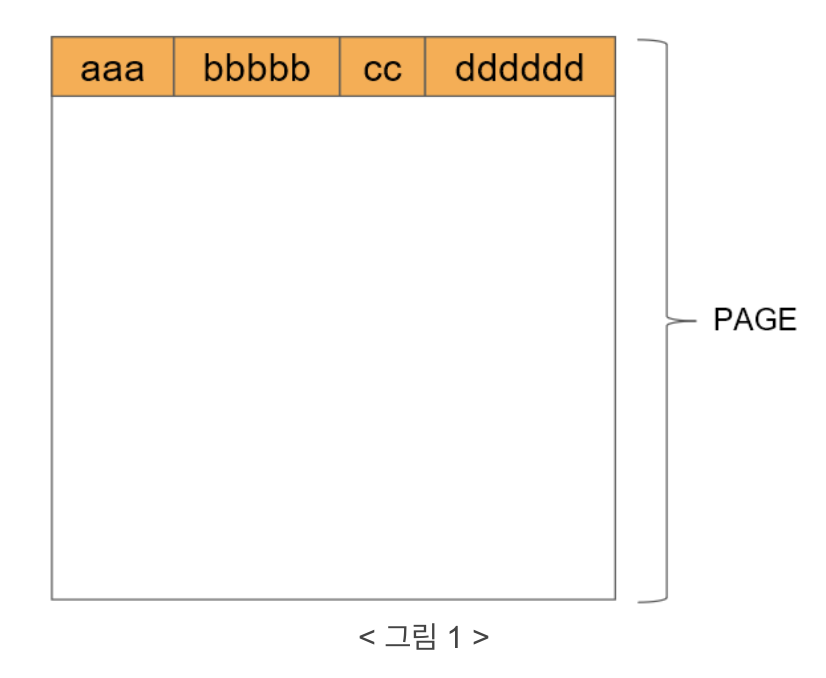
이러면 문제가 ‘bbbbb’의 위치를 어떻게 찾느냐 입니다. 그래서 추가되는 개념이 data header 입니다.
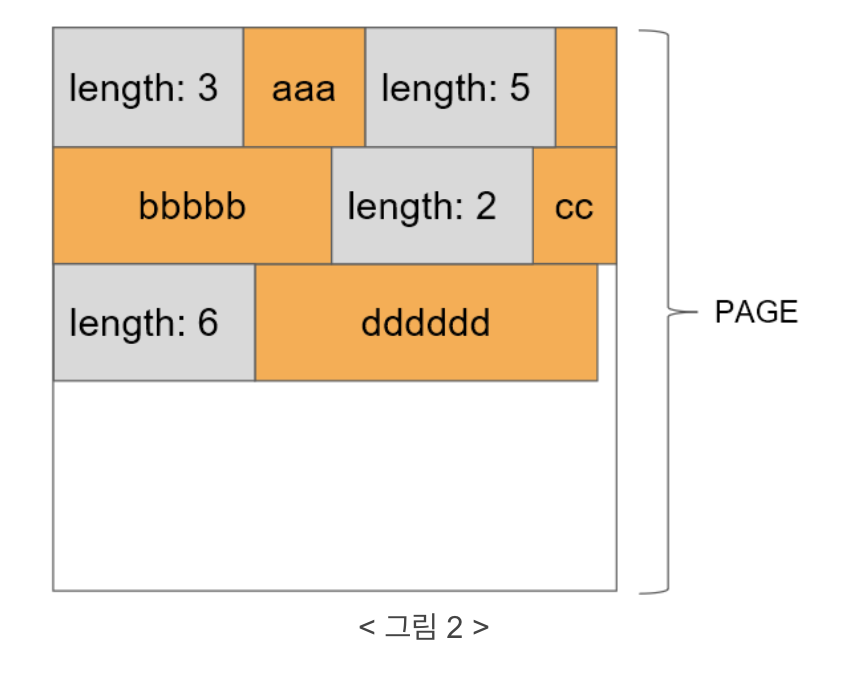
각 데이터의 앞에 길이정보를 가지는 data header를 추가함으로써 data headr 크기 + aaa 길이 = bbbbb의 시작점
같은 방식으로 각 데이터의 위치를 찾을 수 있습니다.
그러면 이제 데이터를 지워보겠습니다.
DELETE FROM t1 WHERE c1 = 'cc';
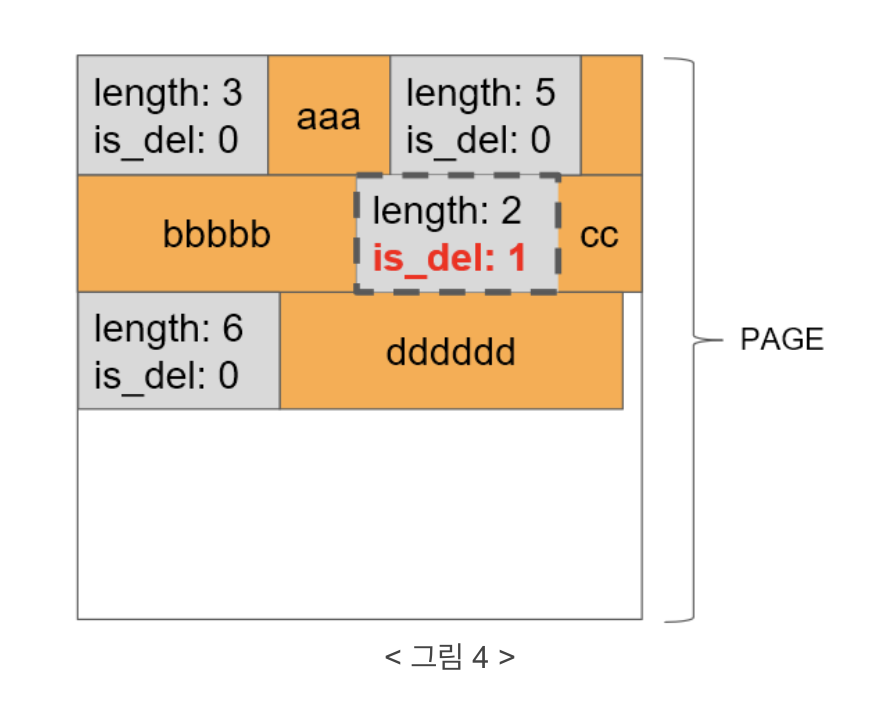
is_del 이라는 삭제 플래그를 두고 추가 insert 등이 발생할 땐 삭제 처리 된 이 영역을 재사용하게 됩니다.
이미 page 단위로 공간이 할당되었기 때문에 이 삭제된 공간만 따로 회수할 수는 없고 이 공간을 재사용하게 되는 것이죠.
이런 공간이 많을 수록 위에서 본 것처럼 OS에서 실제 차지하는 공간과 db 내에서 인식되는 공간간의 차이,
즉 fragmentation 현상이 확인 되는 것입니다.
optimzie 같은 최적화 작업은 데이터를 전부 새로 다시 부어주는 과정이기 때문에 이런 삭제처리된 공간을 회수 할 수 있게 되는 것입니다.
참고로 위와 같은 page 구조는 아주 단순하게 살펴본 구조로 실제로는 아래와 같은 slot page 형태로 이루어지게 됩니다.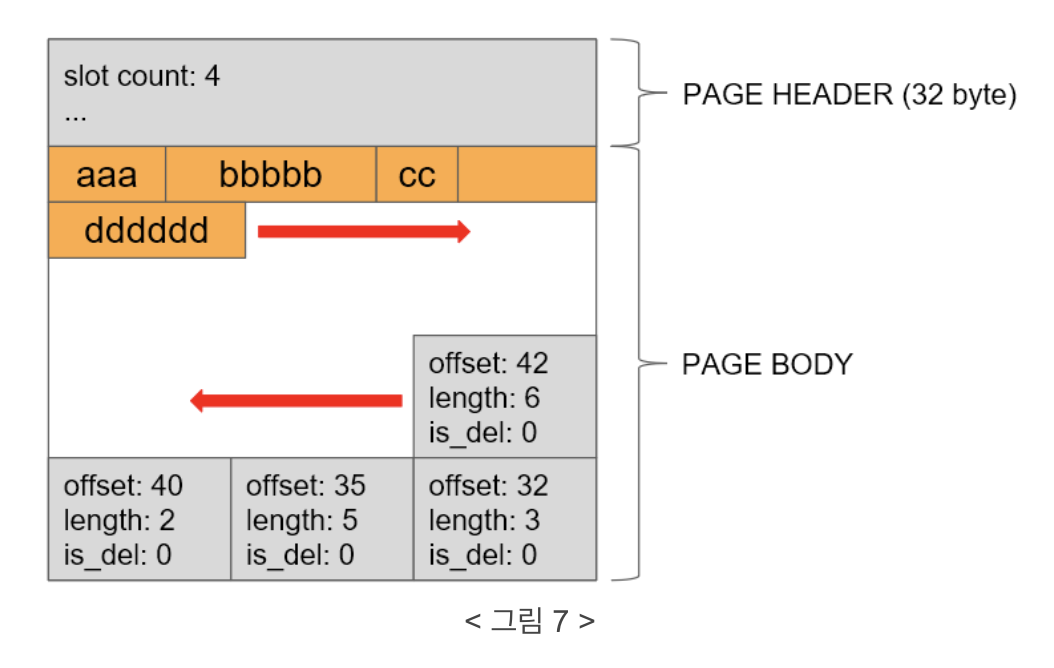
page header에 위치하던 data header가 페이지 끝으로 이동했고
page header에는 현재 페이지에 몇 개의 data header가 있는지를 (slot 개수) 나타내는 정보 등이 기록됩니다.
이 구조에서 데이터는 기존처럼 페이지 시작에서 끝 방향으로 추가되고 data header는 페이지 끝에서 페이지 시작 방향으로 추가되는 구조입니다.
이렇게 함으로써 모든 data header를 사용한 후에도 페이지 내 공간이 남는다거나 반대로, data header 배열을 100% 사용하지 못하는 page 공간 낭비를 피할 수 있게 됩니다.