테스트 배경
- aurora mysql3 (mysql8) 버전업 이후 aurora mysql2 (mysql5.7) 에서는 수행되던 쿼리가 out of sort memory, consider increasing server sort buffer size 에러로 실패하는 케이스 발생
- MySQL에서 sorting 동작 방식은 buffer에 데이터를 올리고, buffer가 꽉차면 tempfile로 떨구고 다시 merge하는 sort & merge 방식이기 때문에 아무리 데이터가 많아도 성능에서 이슈가 있을 뿐, out of sort memory로 쿼리 자체가 실패해버리는 것은 이해가 어려운 동작이었음
- aurora mysql3 (mysql8) 버전에서 어떤 변화가 생겼는지, 어떻게 우회할 수 있을지를 확인해본다
테스트 결론
aurora mysql3 업그레이드 이후, 혹은 새로 개발한 쿼리에서 아래와 같은 에러가 발생한다면,,,
[ERROR] [MY-013131] [Server] Out of sort memory, consider increasing server sort buffer size!
- 아주 간단하게는 파라미터그룹에서 sort_buffer_size를 256KB → 2MB로 늘려준다
- 세션 단위로 적용되는 파라미터라서 동시에 많은 커넥션이 file sorting을 하면 메모리 사용률이 늘어날 수 있어서 적용 전 쿼리 패턴 확인이 필요함
- 그래도 세션이 생길 때마다 세션마다 2MB씩 할당받는 건 아니고, 점진적으로 사용한만큼 늘어나는 방식이라 우려되는 메모리 급등의 위험은 크진 않음
- MySQL이 JSON type을 애매하게 봐줘서 발생한 이슈다. JSON이 반드시 필요한게 아니고, JSON에 해당하는 데이터를 자주 업데이트하는 것이 아니라면, TEXT type으로 변경하는 것도 검토할만하다. json->text로 변경해도 이 이슈는 우회할수 있다.
- 습관성 select * 사용을 지양하자! select 절에 JSON, TEXT 타입을 포함하지 않는 것 만으로도 쿼리 성능은 물론, 이번과 같은 이슈를 피할 수 있다
- query의 order by는 가능하면 index를 타도록 설계하자. 인덱스를 잘 타도록 설계된 쿼리는 order by 가 있어도 sorting을 하지 않는다
시작하기 전에 잠깐 사전지식
MySQL 정렬 방식에 대해 알아보자
기본 컨셉
기본적으로 MySQL에서 자신의 buffer보다 큰 데이터를 대상으로 작업해야할 땐 위 그림과 같은 흐름으로 동작한다
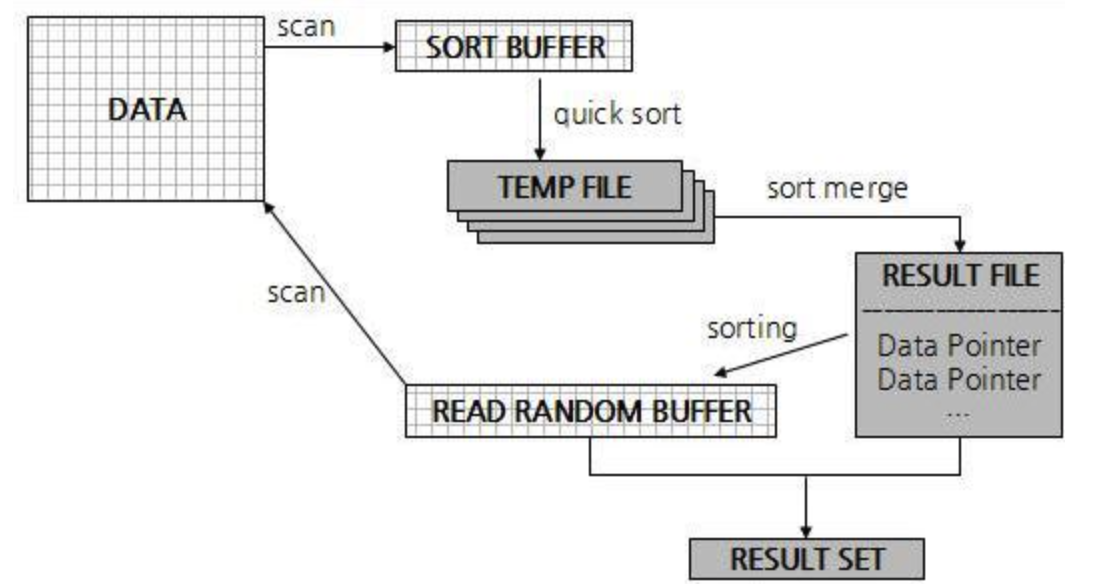
- 작업용 버퍼에 데이터를 올리고
- 그럼에도 작업 대상이 더 남았다면 버퍼에 올린 데이터를 temp file로 떨군다
- 그 temp file들을 merge하고 merge한 값들 끼리 정렬한 뒤
- 결과를 반환한다
이 기본적인 흐름은 sorting 외에도 hash join , 조인컬럼에 인덱스 없는 테이블의 join, index 생성, Rebuild가 필요한 DDL 등등 많은 곳에서 사용된다
sorting에 대해서는 위 흐름을 기반으로, single-pass , two-pass로 방식이 나뉜다.
SELECT emp_no, first_name, last_name
FROM employees
ORDER BY first_name;
이 동일한 쿼리를 처리할때도 single-pass 냐 two-pass냐 동작방식이 다르다
single-pass
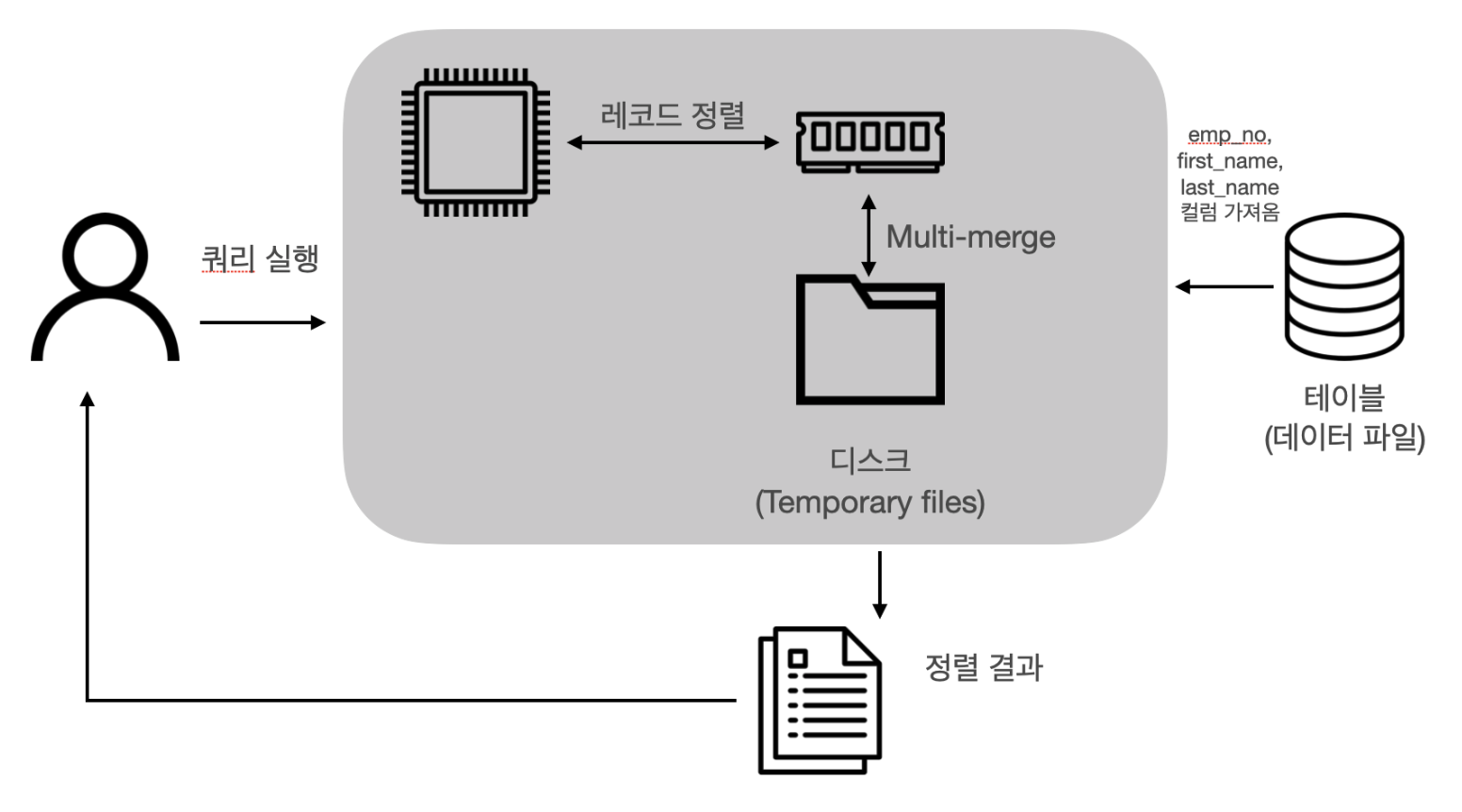
[ real mysql sorting부분 참고]
- order by 컬럼을 포함해 SELECT 하는 컬럼 전부를 sort_buffer에 담아서 sorting하는 방법
- employees 테이블을 읽어올 때 order by에 필요하지 않은 last_name 컬럼까지 전부 읽어서 sort_buffer에 담아서 정렬하고
- 정렬이 완료되면 sort_buffer의 내용을 그대로 클라이언트로 반환하게 됨
two-pass
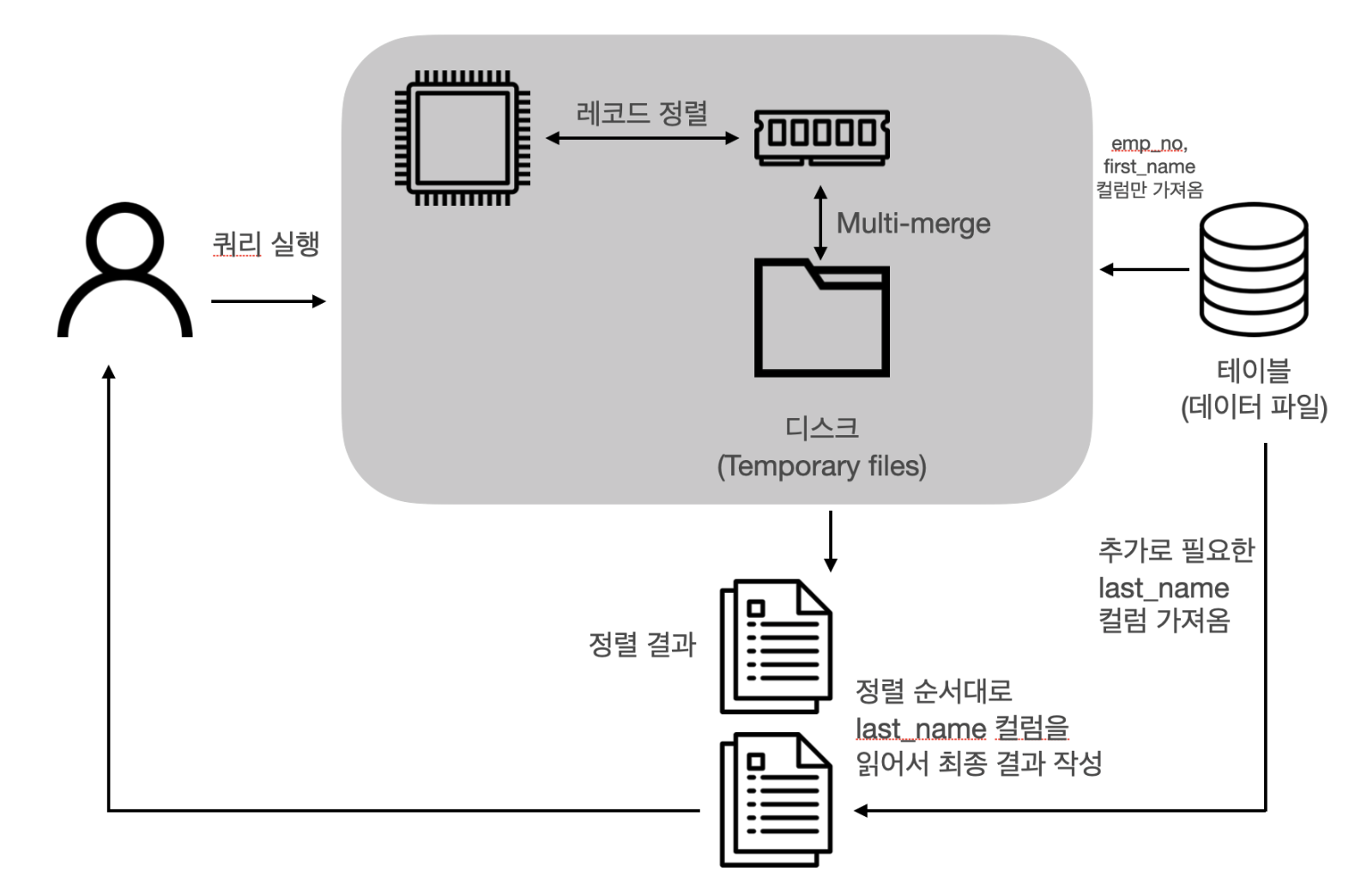
[ real mysql sorting부분 참고]
- order by 대상 컬럼인 first_name 과 PK emp_no만 sort_buffer에 담고 정렬한뒤
- 정렬된 순서대로 다시 테이블에 가서 PK를 정렬된 순서대로 읽어서 나머지 select 하는 컬럼을 가져옴
- first_name+PK 로 한번 읽고, 다시 또 select 컬럼을 가져오기 위해 총 두번 읽어서 two-pass라고 한다
당연히 모든 컬럼을 가지고 sort_buffer에서 작업하는 single-pass 보다는
order by 컬럼 + PK만을 가지고 작업하는 two-pass가 sort_buffer를 조금 더 여유롭게 사용할 수 있으나
single-pass는 한번만 읽으면 된다는 장점덕에 데이터셋이 적당하면 성능상 유리하다는 서로의 장단점이 있다.
MySQL 5.7부터는 single-pass를 기본으로 하되 json, text, blob 이 있는 쿼리는 two-pass로 동작하지만
MySQL 8.0부터는 여기에서 살짝 또 변경이 되어서, JSON,tinyblob 에 대해서는 two-pass가 아니라 single-pass 를 사용할 수 있게 개선이라지만 위험한 변경이 발생해버렸다.
테스트
- 대상 스키마와 쿼리
CREATE TABLE `tb_test` (
`email` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`fullBizNo` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`created` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`modified` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`test_column` json NOT NULL,
`consultNumber` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`email`,`fullBizNo`),
KEY `idx_tb_test_modified` (`modified`),
KEY `idx_tb_test_fullBizNo` (`fullBizNo`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
select * from tb_test
where email = 'test@test.com'
and modified > '2024-05-01'
and modified < '2024-07-08'
order by modified desc
limit 10;
mysql> explain
-> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
+----+-------------+------------+------------+------+---------------------------------+---------+---------+-------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------------------------+---------+---------+-------+------+----------+-----------------------------+
| 1 | SIMPLE | tb_test | NULL | ref | PRIMARY,idx_tb_test_modified | PRIMARY | 402 | const | 12 | 66.41 | Using where; Using filesort |
+----+-------------+------------+------------+------+---------------------------------+---------+---------+-------+------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)
=> test_column 이라는 json 컬럼이 있고 서비스 쿼리에서는 select * + order by 로 정렬을 한다
또한 적절한 인덱스 (email,modified) 가 없어서, (email,fullBizNo) PK를 타게 되었다.
PK를 타게된 이유는 아래에서 더 자세하게 확인하겠다
- 발생 에러
mysql> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc;
2024-08-09T03:52:37.901435Z 16 [ERROR] [MY-013131] [Server] Out of sort memory, consider increasing server sort buffer size!
ERROR 1038 (HY001): Out of sort memory, consider increasing server sort buffer size
디버깅 - 정상적인 sorting의 전체 프로세스
bool filesort(THD *thd, Filesort *filesort, RowIterator *source_iterator, Filesort_info *fs_info, Sort_result *sort_result, ha_rows *found_rows) {
Sort_param *param = &filesort->m_sort_param;
trace_filesort_information(trace, filesort->sortorder, s_length);
param->init_for_filesort(filesort, make_array(filesort->sortorder, s_length), sortlength(thd, filesort->sortorder, s_length), table, max_rows, filesort->m_remove_duplicates);
fs_info->addon_fields = param->addon_fields; // select field에 선언된 컬럼들
thd->inc_status_sort_scan();
## 데이터를 읽어옴
num_rows_found = read_all_rows(thd, param, fs_info, &chunk_file, &tempfile, param->using_pq ? &pq : nullptr, source_iterator, found_rows, &longest_key, &longest_addons);
->for (;;)
->source_iterator->Read()
->++(*found_rows);
######################### 메모리에서 정렬 (priority queue) #########################
->if (pq) ## priority queue, 힙 정렬
->pq->push(ref_pos);
->const uint rec_sz = m_sort_param->make_sortkey(m_sort_keys[m_queue.size()], element_size, element);
.
.
.
//priority queue에서 시도
->m_queue.push(m_sort_keys[m_queue.size()]);
->m_container.push_back(x);
->reverse_heapify(m_container.size() - 1);
->while (i > 0 && !Base::operator()(m_container[i], m_container[parent(i)]))
->std::swap(m_container[parent(i)], m_container[i]);
->i = parent(i);
######################### sort_buffer 사용해서 정렬 #########################
->else
->bool out_of_mem = alloc_and_make_sortkey(param, fs_info, ref_pos, &key_length, &longest_addon_so_far);
->if (out_of_mem)
->if (num_records_this_chunk > 0)
->write_keys(param, fs_info, num_records_this_chunk, chunk_file, tempfile)
->count = fs_info->sort_buffer(param, count);
->return filesort_buffer.sort_buffer(param, count);
.
.
.
.
->for (uint ix = 0; ix < count; ++ix)
->uchar *record = fs_info->get_sorted_record(ix);
->my_b_write(tempfile, record, rec_length)
->num_records_this_chunk = 0;
->fs_info->reset();
->out_of_mem = alloc_and_make_sortkey(param, fs_info, ref_pos, &key_length, &longest_addon_so_far);
->num_records_this_chunk++;
######################### 임시파일 병합 & 정렬 #########################
fs_info->read_chunk_descriptors(&chunk_file, num_chunks);
open_cached_file(outfile, mysql_tmpdir, TEMP_PREFIX, READ_RECORD_BUFFER, MYF(MY_WME))
reinit_io_cache(outfile, WRITE_CACHE, 0L, false, false)
// 임시파일 merge
merge_many_buff(thd, param, merge_buf, fs_info->merge_chunks, &num_chunks, &tempfile)
flush_io_cache(&tempfile)
if (num_chunks == 0) {
//임시 파일이 더이상 없는 경우
save_index(param, rows_in_chunk, fs_info, sort_result)
->sort_result->sorted_result.reset(static_cast<uchar *>(my_malloc(key_memory_Filesort_info_record_pointers, buf_size, MYF(MY_WME))));
->to = sort_result->sorted_result.get()
->for (uint ix = 0; ix < count; ++ix)
->uchar *record = table_sort->get_sorted_record(ix);
->return m_record_pointers[ix];
->uchar *start_of_payload = param->get_start_of_payload(record);
->memcpy(to, start_of_payload, res_length);
->to += res_length;
} else {
merge_index(thd, param, merge_buf, Merge_chunk_array(fs_info->merge_chunks.begin(), num_chunks), &tempfile, outfile)
}
######################### 버퍼 등 리소스 정리 #########################
close_cached_file(&tempfile);
close_cached_file(&chunk_file);
flush_io_cache(outfile)
디버깅 - 이슈 발생 부분
우선,, 본격적으로 확인하기에 앞서
order by sorting을 생략할 수 있게 하는 modified 인덱스 대신
optimizer는 왜 (email,fullbiz) PK를 선택했을지를 간단히 확인해보겠다
### pk 타게되는 과정
>test_quick_select
enter: keys_to_use: 3 prev_tables: 0
opt: range_analysis: starting struct
opt: table_scan: starting struct
opt: rows: 777
opt: cost: 3547.21
opt: table_scan: ending struct
opt: potential_range_indexes: starting struct
opt: (null): starting struct
opt: index: "PRIMARY"
opt: usable: 1
opt: key_parts: starting struct
opt: (null): "email"
opt: (null): "fullBizNo"
opt: key_parts: ending struct
opt: (null): ending struct
opt: (null): starting struct
opt: index: "idx_tb_test_modified"
opt: usable: 1
opt: key_parts: starting struct
opt: (null): "modified"
opt: (null): "email"
opt: (null): "fullBizNo"
opt: key_parts: ending struct
opt: (null): ending struct
opt: (null): starting struct
opt: index: "idx_tb_test_fullBizNo"
opt: usable: 0
opt: cause: "not_applicable"
opt: (null): ending struct
=> 쿼리에서 사용할 수 있는 INDEX 후보들을 추린다.
모두 세개 인덱스가 있지만 써봄직한 인덱스는 PRIMARY, idx_tb_test_modified 두개로 판단된다 (usable 부분 확인)
### PK
opt: range_scan_alternatives: starting struct
opt: (null): starting struct
opt: index: "PRIMARY"
.
.
.
exit: Records: 12
<check_quick_select
opt: ranges: starting struct
opt: (null): "email = 'test@test.com'"
opt: ranges: ending struct
opt: index_dives_for_eq_ranges: 1
opt: rowid_ordered: 1
opt: using_mrr: 0
opt: index_only: 0
opt: in_memory: 0.00825228
opt: rows: 12
opt: cost: 2.21803
opt: chosen: 1
opt: (null): ending struct
opt: (null): starting struct
=> PK는 sorting을 해야하지만, email 조건으로 읽어야하는 row가 12건밖에 안되고 , cost가 2.2로 매우 낮다
### idx_tb_test_modified
opt: (null): starting struct
opt: index: "idx_tb_test_modified"
.
.
<check_quick_select
opt: ranges: starting struct
opt: (null): "'2024-05-01 00:00:00.000000' < modified < '2024-07-08 00:00:00.000000'"
opt: ranges: ending struct
opt: index_dives_for_eq_ranges: 1
opt: rowid_ordered: 0
opt: using_mrr: 0
opt: index_only: 0
opt: in_memory: 0.25
opt: rows: 516
opt: cost: 565.41
opt: chosen: 0
opt: cause: "cost"
opt: (null): ending struct
=> idx_tb_test_modified 는 sorting은 안해도 되지만 이 조건으로 읽어야하는 Rows가 516건이다.
idx_tb_test_modified는 읽어야할 rows가 많으니 cost도 PK 2.2보다 높은 565이다.
그래서 cause : “cost” 로 선택받지 못하였다.
<make_join_query_block
>JOIN::optimize_distinct_group_order
opt: (null): starting struct
opt: optimizing_distinct_group_by_order_by: starting struct
>JOIN::remove_const
opt: simplifying_order_by: starting struct
opt: original_clause: "`tb_test`.`modified` desc"
opt: items: starting struct
>JOIN::update_depend_map
<JOIN::update_depend_map
opt: (null): starting struct
opt: item: "`tb_test`.`modified`"
opt: (null): ending struct
exit: simple_order: 1
opt: items: ending struct
opt: resulting_clause_is_simple: 1
opt: resulting_clause: "`tb_test`.`modified` desc"
opt: simplifying_order_by: ending struct
.
.
.
>test_if_order_by_key
<test_if_order_by_key
<test_if_cheaper_ordering
opt: steps: ending struct
opt: index_order_summary: starting struct
opt: table: "`tb_test`"
opt: index_provides_order: 0
opt: order_direction: "undefined"
opt: index: "PRIMARY"
=> 그래서 쿼리는 PRIMARY 인덱스를 사용하게 되었고
tb_test.modified desc 조건으로 order by sorting을 하게 된다.
여기까지는 PRIMARY를 선택하는 것 까지의 optimizer의 판단은 충분히 납득가능하다.
sorting을 하게 되었지만, sorting을 하더라도 위의 사전지식 부분에서 본것처럼
데이터가 너무 많으면 임시파일을 생성하고 merge하는 식으로라도 결국엔 수행이 되어야할 것이다.
근데 왜 Out of Sort Memory 에러가 발생하면서 쿼리가 오래 걸리는 것도 아니고 아주 실패를 해버렸을까?
아래부터는 그 원인에 대해서 자세하게 살펴보겠다.
- 정렬 방법 선택하는 부분 - single pass냐,,, two pass(RowID)냐,,,
bool SortWillBeOnRowId(TABLE *table) {
.
.
.
for (Field **pfield = table->field; *pfield != nullptr; ++pfield) {
Field *field = *pfield;
if (!bitmap_is_set(table->read_set, field->field_index())) continue;
if (field->type() == MYSQL_TYPE_BLOB &&
field->max_packed_col_length() > 70000u) {
return true;
}
}
return false;
}
=> query하는 테이블 컬럼의 타입을 하나하나씩 확인한다.
만약 컬럼이 BLOB 타입이면 true를 return하고
위에서 살펴본 정렬 방식 중 PK+정렬 키로 먼저 정렬한 뒤 그 순서대로 다시 테이블을 조회해서 리턴하는 two-pass
(PK를 사용한다하여 ROWID 방식이라 한다) 방식으로 풀리게 될 것이다.
(gdb) p *(field)
$33 = {_vptr.Field = 0x823e6e8 <vtable for Field_varstring+16>, ptr = 0xfffe7c004a31 "\032", m_hidden = dd::Column::HT_VISIBLE, m_null_ptr = 0x0, m_is_tmp_nullable = false, m_is_tmp_null = false,
m_check_for_truncated_fields_saved = CHECK_FIELD_IGNORE, static dummy_null_buffer = 32 ' ', table = 0xfffe7c117760, orig_db_name = 0x0, orig_table_name = 0x0, table_name = 0xfffe7c1178b8,
field_name = 0xfffe78a5ea10 "email", comment = {str = 0x62479d8 "", length = 0}, key_start = {map = 1}, part_of_key = {map = 7}, part_of_prefixkey = {map = 0}, part_of_sortkey = {map = 7},
part_of_key_not_extended = {map = 1}, static MAX_VARCHAR_WIDTH = 65535, static MAX_TINY_BLOB_WIDTH = 255, static MAX_SHORT_BLOB_WIDTH = 65535, static MAX_MEDIUM_BLOB_WIDTH = 16777215,
static MAX_LONG_BLOB_WIDTH = 4294967295, field_length = 400, flags = 20483, m_field_index = 0, null_bit = 0 '\000', auto_flags = 0 '\000', is_created_from_null_item = false, m_indexed = true,
m_engine_attribute = {str = 0x6243068 "", length = 0}, m_secondary_engine_attribute = {str = 0x6243068 "", length = 0}, m_warnings_pushed = 0, gcol_info = 0x0, stored_in_db = true, m_default_val_expr = 0x0}
(gdb) p field->type() == MYSQL_TYPE_BLOB
$34 = false
(gdb) p field->type()
$35 = MYSQL_TYPE_VARCHAR
.
.
.
(gdb) p *(field)
$39 = {_vptr.Field = 0x8240668 <vtable for Field_timestampf+16>, ptr = 0xfffe7c004c14 "", m_hidden = dd::Column::HT_VISIBLE, m_null_ptr = 0x0, m_is_tmp_nullable = false, m_is_tmp_null = false,
m_check_for_truncated_fields_saved = CHECK_FIELD_IGNORE, static dummy_null_buffer = 32 ' ', table = 0xfffe7c117760, orig_db_name = 0x0, orig_table_name = 0x0, table_name = 0xfffe7c1178b8,
field_name = 0xfffe78a5ec20 "created", comment = {str = 0x62479d8 "", length = 0}, key_start = {map = 0}, part_of_key = {map = 0}, part_of_prefixkey = {map = 0}, part_of_sortkey = {map = 0},
part_of_key_not_extended = {map = 0}, static MAX_VARCHAR_WIDTH = 65535, static MAX_TINY_BLOB_WIDTH = 255, static MAX_SHORT_BLOB_WIDTH = 65535, static MAX_MEDIUM_BLOB_WIDTH = 16777215,
static MAX_LONG_BLOB_WIDTH = 4294967295, field_length = 26, flags = 1153, m_field_index = 2, null_bit = 0 '\000', auto_flags = 2 '\002', is_created_from_null_item = false, m_indexed = false,
m_engine_attribute = {str = 0x6243068 "", length = 0}, m_secondary_engine_attribute = {str = 0x6243068 "", length = 0}, m_warnings_pushed = 0, gcol_info = 0x0, stored_in_db = true, m_default_val_expr = 0x0}
(gdb) p field->type()
$40 = MYSQL_TYPE_TIMESTAMP
.
.
.
(gdb) p *field
$44 = {_vptr.Field = 0x823ddb8 <vtable for Field_json+16>, ptr = 0xfffe7c004c22 "", m_hidden = dd::Column::HT_VISIBLE, m_null_ptr = 0x0, m_is_tmp_nullable = false, m_is_tmp_null = false,
m_check_for_truncated_fields_saved = CHECK_FIELD_IGNORE, static dummy_null_buffer = 32 ' ', table = 0xfffe7c117760, orig_db_name = 0x0, orig_table_name = 0x0, table_name = 0xfffe7c1178b8,
field_name = 0xfffe78a5ee18 "test_column", comment = {str = 0x62479d8 "", length = 0}, key_start = {map = 0}, part_of_key = {map = 0}, part_of_prefixkey = {map = 0}, part_of_sortkey = {map = 0},
part_of_key_not_extended = {map = 0}, static MAX_VARCHAR_WIDTH = 65535, static MAX_TINY_BLOB_WIDTH = 255, static MAX_SHORT_BLOB_WIDTH = 65535, static MAX_MEDIUM_BLOB_WIDTH = 16777215,
static MAX_LONG_BLOB_WIDTH = 4294967295, field_length = 4294967295, flags = 4241, m_field_index = 4, null_bit = 0 '\000', auto_flags = 0 '\000', is_created_from_null_item = false, m_indexed = false,
m_engine_attribute = {str = 0x6243068 "", length = 0}, m_secondary_engine_attribute = {str = 0x6243068 "", length = 0}, m_warnings_pushed = 0, gcol_info = 0x0, stored_in_db = true, m_default_val_expr = 0x0}
(gdb) n
2213 if (field->type() == MYSQL_TYPE_BLOB &&
(gdb) p field->type()
$45 = MYSQL_TYPE_JSON
.
.
.
(gdb) n
2191 for (Field **pfield = table->field; *pfield != nullptr; ++pfield) {
(gdb) n
2218 return false;
=> 그러나 내가 조회하는 테이블과 쿼리는 확인 결과 비록 JSON일지언정 BLOB은 아니다.
그래서 결국 return false를 하여 RowID (two-pass) 가 아닌 single-pass 로 정렬하게 된다.
- single-pass 로 정렬하게 되므로 addon fields, 즉 select 절에 포함된 컬럼에 대한 길이와 컬럼 타입 등의 정보가 필요하다
$53 = {_vptr.Field = 0x823e6e8 <vtable for Field_varstring+16>, ptr = 0xfffe7c004a31 "\032", m_hidden = dd::Column::HT_VISIBLE, m_null_ptr = 0x0, m_is_tmp_nullable = false, m_is_tmp_null = false,
m_check_for_truncated_fields_saved = CHECK_FIELD_IGNORE, static dummy_null_buffer = 32 ' ', table = 0xfffe7c117760, orig_db_name = 0x0, orig_table_name = 0x0, table_name = 0xfffe7c1178b8,
field_name = 0xfffe78a5ea10 "email", comment = {str = 0x62479d8 "", length = 0}, key_start = {map = 1}, part_of_key = {map = 7}, part_of_prefixkey = {map = 0}, part_of_sortkey = {map = 7},
part_of_key_not_extended = {map = 1}, static MAX_VARCHAR_WIDTH = 65535, static MAX_TINY_BLOB_WIDTH = 255, static MAX_SHORT_BLOB_WIDTH = 65535, static MAX_MEDIUM_BLOB_WIDTH = 16777215,
static MAX_LONG_BLOB_WIDTH = 4294967295, field_length = 400, flags = 20483, m_field_index = 0, null_bit = 0 '\000', auto_flags = 0 '\000', is_created_from_null_item = false, m_indexed = true,
m_engine_attribute = {str = 0x6243068 "", length = 0}, m_secondary_engine_attribute = {str = 0x6243068 "", length = 0}, m_warnings_pushed = 0, gcol_info = 0x0, stored_in_db = true, m_default_val_expr = 0x0}
(gdb) n
2283 const uint field_length = field->max_packed_col_length();
(gdb) p field_length
$54 = 65535
(gdb) p field->max_packed_col_length()
$55 = 402
(gdb)n
2284 AddWithSaturate(field_length, &total_length);
(gdb) p field_length
$56 = 402
(gdb) p &total_length
$57 = (uint *) 0xffff64161c14
(gdb) p *(&total_length)
$58 = 0
(gdb) n
2286 const enum_field_types field_type = field->type();
(gdb) p *(&total_length)
$59 = 402
(gdb) p field_type
$60 = MYSQL_TYPE_VARCHAR
=> 먼저 email 컬럼을 보면 varchar(100)에 utf8mb4 charset이다
그러므로 해당 컬럼의 length를 확인하면, 4*100 + 2bytes(문자열 기준 255bytes 이상이면 2 bytes, 미만이면 1bytes가 추가된다) 로 402 bytes가 된다
그래서 마지막줄에서 보이듯, email column은 402bytes, VARCHAR 타입인 것을 확인할 수 있다.
이 동작을 select 에 선언된 모든 컬럼에 대해 반복한다
(gdb) p *(field)
$84 = {_vptr.Field = 0x823ddb8 <vtable for Field_json+16>, ptr = 0xfffe7c004c22 "", m_hidden = dd::Column::HT_VISIBLE, m_null_ptr = 0x0, m_is_tmp_nullable = false, m_is_tmp_null = false,
m_check_for_truncated_fields_saved = CHECK_FIELD_IGNORE, static dummy_null_buffer = 32 ' ', table = 0xfffe7c117760, orig_db_name = 0x0, orig_table_name = 0x0, table_name = 0xfffe7c1178b8,
field_name = 0xfffe78a5ee18 "test_column", comment = {str = 0x62479d8 "", length = 0}, key_start = {map = 0}, part_of_key = {map = 0}, part_of_prefixkey = {map = 0}, part_of_sortkey = {map = 0},
part_of_key_not_extended = {map = 0}, static MAX_VARCHAR_WIDTH = 65535, static MAX_TINY_BLOB_WIDTH = 255, static MAX_SHORT_BLOB_WIDTH = 65535, static MAX_MEDIUM_BLOB_WIDTH = 16777215,
static MAX_LONG_BLOB_WIDTH = 4294967295, field_length = 4294967295, flags = 4241, m_field_index = 4, null_bit = 0 '\000', auto_flags = 0 '\000', is_created_from_null_item = false, m_indexed = false,
m_engine_attribute = {str = 0x6243068 "", length = 0}, m_secondary_engine_attribute = {str = 0x6243068 "", length = 0}, m_warnings_pushed = 0, gcol_info = 0x0, stored_in_db = true, m_default_val_expr = 0x0}
(gdb)
(gdb) p field_type
$89 = MYSQL_TYPE_JSON
2291 AddWithSaturate(field_length, &packable_length);
(gdb) p field_length
$90 = 4294967295
.
.
.
2301 *ppackable_length = packable_length;
(gdb) p packable_length
$99 = 4294967295
2359 DBUG_PRINT("info", ("addon_length: %d", length));
(gdb) p length
$139 = 4294967295
=> 문제는 JSON 타입인 test_column 인데
test_column의 length는 4294967295 이고 이는 4 bytes integer값의 최대 길이다
그래서 이 쿼리의 addon-fields들의 total length는 4294967295가 되고
이 값은 이따가 이 쿼리가 단순히 메모리에서만 정렬이 가능할지 확인하는 용도로 사용된다
### 쿼리하는 데이터의 정보
<count_field_types
info: addon_field email max_length 402
info: addon_field fullBizNo max_length 81
info: addon_field created max_length 7
info: addon_field modified max_length 7
info: addon_field test_column max_length 4294967295
info: addon_field consultNumber max_length 41
info: addon_length: -1
>JOIN::push_to_engines
위 과정을 모두 마치고 나면 위 처럼 length와 컬럼 타입 조사가 끝나게된다.
그럼 이제 조사 결과를 바탕으로 이 쿼리를 메모리에서 돌릴 수 있을지, 임시파일을 생성하고 merge 하면서 작업을 돌려야할지를 확인하는 과정으로 넘어가자
- 이 쿼리를 메모리에서만 정렬할수 있을지 체크
bool check_if_pq_applicable(Opt_trace_context *trace, Sort_param *param,
Filesort_info *filesort_info, ha_rows num_rows,
ulong memory_available) {
.
.
.
if (param->max_record_length() >= 0xFFFFFFFFu) {
trace_filesort.add("usable", false)
.add_alnum("cause", "contains records of unbounded length");
return false;
}
(gdb) p param->max_record_length()
$166 = 4294967295
filesort (thd=0xfffe7c010780, filesort=0xfffe7c157de8, source_iterator=0xfffe7c1588d8, tables_to_get_rowid_for=0, num_rows_estimate=12, fs_info=0xfffe7c158920, sort_result=0xfffe7c1589a8,
found_rows=0xffff641629b0) at /mysql_source/mysql-8.0.32/sql/filesort.cc:475
475 DBUG_PRINT("info", ("filesort PQ is not applicable"));
=> MySQL 내부에는 priority queue 라는 데이터 처리 시 사용할 수 있는 메모리구조가 있다
정렬, union all 등을 할때 데이터가 얼마 안되면 priority queue에서 얼른 작업 후 결과를 리턴하는 용도로,
이 버퍼의 크기는 dba가 정할 순 없는데
이 쿼리를 처리할 때도 우선 priority queue를 사용할 수 있을지 확인하게 된다.
근데 위에서 확인했듯 이 쿼리의 addon-fields의 total elngth는 4294967295이고,
if (param->max_record_length() >= 0xFFFFFFFFu )
여기에 걸려서 결국 False를 반환하고 priority queue를 사용할 수 없게 된다.
0xFFFFFFFFu 는 unsinged int의 최대값으로 4294967295(16진수) 를 의미한다.
>check_if_pq_applicable
opt: filesort_priority_queue_optimization: starting struct
opt: limit: 10
opt: usable: 0
opt: cause: "contains records of unbounded length"
- priority queue 를 사용하지 못하게 된 이 쿼리,,, 어떻게 풀어야하는가
DBUG_PRINT("info", ("filesort PQ is not applicable"));
filesort->using_pq = false;
param->using_pq = false;
/*
When sorting using prioritnny queue, we cannot use packed addons.
Without PQ, we can try.
*/
param->try_to_pack_addons();
/*
NOTE: param->max_rows_per_buffer is merely informative (for optimizer
trace) in this case, not actually used.
*/
if (num_rows_estimate < MERGEBUFF2) num_rows_estimate = MERGEBUFF2;
ha_rows keys =
memory_available / (param->max_record_length() + sizeof(char *));
param->max_rows_per_buffer =
min(num_rows_estimate > 0 ? num_rows_estimate : 1, keys);
fs_info->set_max_size(memory_available, param->max_record_length());
}
495 fs_info->set_max_size(memory_available, param->max_record_length());
(gdb) p memory_available
$170 = 262144
(gdb) p *(fs_info)
$172 = {filesort_buffer = {m_next_rec_ptr = 0x0, m_current_block_end = 0x0, m_blocks = std::vector of length 0, capacity 0, m_record_pointers = std::vector of length 0, capacity 0,
m_max_record_length = 4294967295, m_max_size_in_bytes = 262144, m_current_block_size = 0, m_space_used_other_blocks = 0, m_peak_memory_used = 0}, merge_chunks = {m_array = 0x0, m_size = 0},
addon_fields = 0xfffe7c1582d8, m_using_varlen_keys = false, m_sort_length = 0}
=> DB에 sort_buffer_size로 할당된 262144 (256KB)를 가지고 데이터를 한 건씩 읽기 시작한다
그리고 sort_buffer가 꽉차게 되면 위에서 본 것처럼 Temp file로 떨구고 이를 merge하는 식으로 풀어나가게 된다.
Opt_trace_array ota(trace, "filesort_execution");
num_rows_found = read_all_rows(
thd, param, filesort->tables, tables_to_get_rowid_for, fs_info,
&chunk_file, &tempfile, param->using_pq ? &pq : nullptr,
source_iterator, found_rows, &longest_key, &longest_addons);
.
.
.
static ha_rows read_all_rows(
THD *thd, Sort_param *param, const Mem_root_array<TABLE *> &tables,
table_map tables_to_get_rowid_for, Filesort_info *fs_info,
IO_CACHE *chunk_file, IO_CACHE *tempfile,
Bounded_queue<uchar *, uchar *, Sort_param, Mem_compare_queue_key> *pq,
RowIterator *source_iterator, ha_rows *found_rows, size_t *longest_key,
size_t *longest_addons) {
.
.
.
++(*found_rows);
num_total_records++;
(gdb) p *(found_rows)
$175 = 1
(gdb) p *(found_rows)
$177 = 2
(gdb) p *(found_rows)
$179 = 3
=> 이런식으로 found_rows에서 볼수있듯 한건씩 쭉 읽는데,,,,
3 row까지 읽고 팍 죽어버린다
// If we're still out of memory after flushing to disk, give up.
if (out_of_mem_or_error) {
if (thd->is_error()) {
return HA_POS_ERROR;
}
my_error(ER_OUT_OF_SORTMEMORY, ME_FATALERROR);
LogErr(ERROR_LEVEL, ER_SERVER_OUT_OF_SORTMEMORY);
return HA_POS_ERROR;
}
}
1007 bool out_of_mem_or_error = alloc_and_make_sortkey(
(gdb)
1009 if (out_of_mem_or_error) {
(gdb)
1010 if (thd->is_error()) {
(gdb)
1014 if (num_records_this_chunk > 0) {
(gdb)
1015 if (write_keys(param, fs_info, num_records_this_chunk, chunk_file,
(gdb)
1019 num_records_this_chunk = 0;
(gdb)
1020 num_written_chunks++;
(gdb)
1021 fs_info->reset();
(gdb)
1024 out_of_mem_or_error = alloc_and_make_sortkey(
(gdb)
1029 if (out_of_mem_or_error) {
(gdb)
1030 if (thd->is_error()) {
(gdb)
1033 my_error(ER_OUT_OF_SORTMEMORY, ME_FATALERROR);
(gdb)
1034 LogErr(ERROR_LEVEL, ER_SERVER_OUT_OF_SORTMEMORY);
(gdb)p out_of_mem_or_error
$180 = true
(gdb) p out_of_mem_or_error
$181 = true
(gdb) n
1035 return HA_POS_ERROR;
=> out_of_mem_or_error 가 true로 떨어지면서
DB에서도 드디어 그 에러가 발생한다.
아니 sort_buffer가 꽉차면 버퍼의 데이터를 temp file로 떨구고 비우고 다시 데이터를 받아야지 왜 아예 실패가 되버리는걸까?
mysql> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc;
2024-08-09T03:52:37.901435Z 16 [ERROR] [MY-013131] [Server] Out of sort memory, consider increasing server sort buffer size!
ERROR 1038 (HY001): Out of sort memory, consider increasing server sort buffer size
데이터를 읽는 것은 아래와 같이 확인할 수 있는데
### 1 rows
T@7: | | | | | | | | | | | | | >lob::read
T@7: | | | | | | | | | | | | | | >lob::data_page_t::read
T@7: | | | | | | | | | | | | | | | lob: page_no=1051
T@7: | | | | | | | | | | | | | | | lob: 65f621 3565f623 3565f625 3565f627 3565f629 3565f62b 3565f62d 3565f62f 3565f631 3565f633 3565f635 3565f637 3565f639 3565f63b 3565f63c4 3565f63cc 3565f63d1 3565f63d3 3565f63d44 3565f63d4c 3565f63d51 3565f63d524 3565f63d52c 3565f63d53c 3565f63d544 3565f63d57 3565f63d5c 3565f63d7 3565f63dc 3565f63f 3565f641 3565f643 3565f645 3565f647 3565f649 3565f64b
.
.
.
### 2 rows
T@7: | | | | | | | | | | | | | | <lob::data_page_t::read
T@7: | | | | | | | | | | | | | | >lob::data_page_t::read
T@7: | | | | | | | | | | | | | | | lob: page_no=1052
T@7: | | | | | | | | | | | | | | | lob: e11c 356f59e13 356f59e144 356f59e14c 356f59e154 356f59e15b 356f59e16b 356f59e1ab 356f59e3ff 356f59e404 356f59e40f4 356f59e40fc 356f59e4104 356f59e410c 356f59e4174 356f59e417c 356f59e41c 356f59e424 356f59e42c 356f59e431 356f59e433 356f59e435 356f59e4364 356f59e436c 356f59e4374 356f59e4394 356f59e439c 356f59e43b 356f59e43d 356f59e44ac 356f59e558c 356f59e55dc 356f59e55f 356f59e561 356f59e563 356f59e565 356f59e5664 356f59e566c 356f59e5674 356f59e56f4 356f59e56fc 356f59e571 356f59e573c 356f59e5744 356f59e5754 356f59e575c 356f59e577 356f59e57c 356f59e59 356f59e5a04
.
.
.
### 3 rows
T@7: | | | | | | | | | | | | | | <lob::data_page_t::read
T@7: | | | | | | | | | | | | | | >lob::data_page_t::read
T@7: | | | | | | | | | | | | | | | lob: page_no=1053
T@7: | | | | | | | | | | | | | | | lob: $ . 8 B M X c m w ) 2 ; D M V _ i s } ( 4 > H R \ f r | # - 7 A K U _ i s }
f2c7 356f5f2cc 356f5f2d4 356f5f2d9fc 356f5f2da4 356f5f2dac 356f5f32c 356f5f3317 356f5f331c 356f5f333 356f5f335 356f5f34b 356f5f34cc OWN_DELIVERY OWN_DELIVERY b * . breakTimesoperationHours 4 D s ' - 5 > J V r allDayopenTimecloseTimecloseNextDayintervalCode hourminute hourminute MON
.
.
.
#### 다음 row는 읽지 못하고 에러가 발생한다
T@7: | | | | | | | | >my_error
T@7: | | | | | | | | | my: nr: 1038 MyFlags: 1024 errno: 11
T@7: | | | | | | | | | >my_message_sql
T@7: | | | | | | | | | | error: error: 1038 message: 'Out of sort memory, consider increasing server sort buffer size'
T@7: | | | | | | | | | | >THD::raise_condition
T@7: | | | | | | | | | | | >mysql_audit_acquire_plugins
T@7: | | | | | | | | | | | <mysql_audit_acquire_plugins
T@7: | | | | | | | | | | | >Diagnostics_area::set_error_status
T@7: | | | | | | | | | | | <Diagnostics_area::set_error_status
T@7: | | | | | | | | | | <THD::raise_condition
T@7: | | | | | | | | | <my_message_sql
T@7: | | | | | | | | <my_error
T@7: | | | | | | | | >log_line_submit
T@7: | | | | | | | | | >log_write_errstream
T@7: | | | | | | | | | | enter: buffer: 2024-07-28T12:33:48.860950Z 7 [ERROR] [MY-013131] [Server] Out of sort memory, consider increasing server sort buffer size!
=> 즉, 이 쿼리는 PQ를 쓰지 못하므로 임시파일을 쓰던 sort_buffer에서 정렬을 하든
sort_buffer에 데이터를 올린 뒤 작업을 해야하는데
하나의 데이터가 sort_buffer_size (256KB) 보다 커서 sort_buffer에 아예 담을 수 조차 없어서 Out of sort memory 에러가 발생하는 것!
<save_index
opt: filesort_summary: starting struct
opt: memory_available: 262144
opt: key_size: 8
opt: row_size: 4294967295
opt: max_rows_per_buffer: 0
opt: num_rows_estimate: 15
opt: num_rows_found: 10
opt: num_initial_chunks_spilled_to_disk: 0
opt: peak_memory_used: 1048640
opt: sort_algorithm: "std::sort"
opt: sort_mode: "<fixed_sort_key, packed_additional_fields>"
opt: filesort_summary: ending struct
사용가능한 메모리는 262144 (256KB)인데 peak_memory_used 를 보면 1048640 (1MB)이다. 아마 4번째 row가 거의 1MB 가까이 되어서 sort_buffer_size에 담을수 조차 없어서 에러가 발생한 것으로 보인다.
해결 방안
######################## 원본 쿼리 -- 실패. ########################
mysql> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
ERROR 1038 (HY001): Out of sort memory, consider increasing server sort buffer size
######################## sort_buffer_size 늘리기 -- 성공 ########################
mysql> set sort_buffer_size = 1024*1024*2;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
.
.
10 rows in set (0.12 sec)
######################## json -> text 변경 후 쿼리 -- 성공. ########################
CREATE TABLE `tb_test2` (
`email` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`fullBizNo` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`created` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`modified` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
`test_column` longtext COLLATE utf8mb4_general_ci NOT NULL,
`consultNumber` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`email`,`fullBizNo`),
KEY `tb_test` (`modified`),
KEY `idx_tb_test_fullBizNo` (`fullBizNo`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
mysql> select * from tb_test2
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
.
.
10 rows in set (0.13 sec)
######################## select 절에 json 컬럼 제외하기 -- 성공. ########################
mysql> select email,fullBizNo,created,modified,consultNumber from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
+----------------------------+------------+----------------------------+----------------------------+---------------+
| email | fullBizNo | created | modified | consultNumber |
+----------------------------+------------+----------------------------+----------------------------+---------------+
| test@test.com | 7943201181 | 2024-07-05 05:06:02.312102 | 2024-07-05 05:25:30.376230 | NULL |
| test@test.com | 7851202500 | 2024-06-28 08:09:44.012014 | 2024-07-01 01:07:07.593431 | NULL |
| test@test.com | 3670502658 | 2024-06-26 08:08:54.819427 | 2024-06-26 08:08:54.819428 | NULL |
| test@test.com | 7831502636 | 2024-06-21 10:01:16.521904 | 2024-06-21 10:01:16.521905 | NULL |
| test@test.com | 6862901594 | 2024-06-21 06:54:16.524653 | 2024-06-21 06:54:16.524655 | NULL |
| test@test.com | 1873901062 | 2024-06-17 08:49:00.700059 | 2024-06-18 02:31:33.233424 | NULL |
| test@test.com | 7565200776 | 2024-06-13 09:02:18.986774 | 2024-06-13 09:02:18.986774 | NULL |
| test@test.com | 1475100863 | 2024-05-31 06:16:10.623935 | 2024-05-31 06:16:10.623937 | NULL |
| test@test.com | 4331302853 | 2024-05-31 01:46:57.208892 | 2024-05-31 01:46:57.208896 | NULL |
| test@test.com | 1332545902 | 2024-05-28 07:08:11.912278 | 2024-05-28 07:08:11.912279 | NULL |
+----------------------------+------------+----------------------------+----------------------------+---------------+
10 rows in set (0.00 sec)
######################## 적절한 인덱스 걸어줘서 sorting 피하기 -- 성공. ########################
mysql> alter table tb_test add index idx_test(email,modified);
Query OK, 0 rows affected (0.12 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from tb_test
-> where email = 'test@test.com'
-> and modified > '2024-05-01'
-> and modified < '2024-07-08'
-> order by modified desc
-> limit 10;
.
.
10 rows in set (0.10 sec)
정리
- MySQL 8.0 부터 json 컬럼에 대한 Sorting 방식이 변경되었다
- 이로 인해 mysql 5.7 에서 잘 돌던 쿼리도 8.0에서는 out of sort memory 에러가 발생하면서 쿼리가 실패할 수 있다.
- 실패하게 되는 이유는, 데이터가 너무 커서 레코드 하나도 sort_buffer_size에 올릴 수 없는 경우, single-pass, two-pass고, temp file & merge고 뭐고 그냥 실패해버린다
- 해결 방법은
- sort_buffer 사이즈를 늘려주거나
- (가능하다면) json 을 text 타입으로 변경해버리거나
- select 절에서 json 같은 무거운 컬럼을 제외하거나
- 쿼리의 order by 부분이 index를 타도록 잘 설계하여 file sorting부분을 아예 없애버리면 된다