ORACLE Architecture 간단히 살펴보기
Oracle Architecture
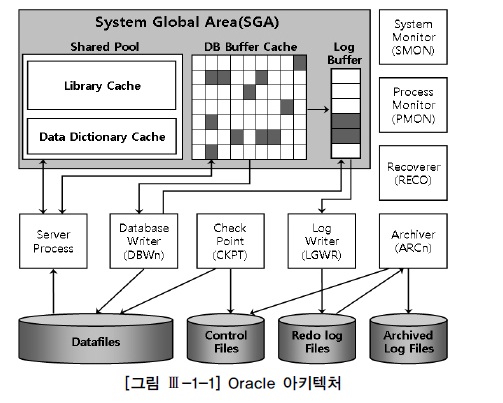
Oracle server는 크게 세부분으로 나뉩니다.
( SGA + Background Process + Files)
메모리 영역 (SGA)
SGA는 shared global area 라는 이름에서부터 알 수 있듯이
사용자들이 오라클에서 데이터를 읽거나 변경하기 위해 사용하는 공용 메모리 영역을 의미합니다.
SGA는 크게 Data buffer cache, Redo log buffer , Shared pool 로 이루어져 있습니다.
- Data buffer cache
데이터의 조회와 변경 등의 실제 작업이 일어나는 공간으로
사용자가 찾거나 변경하는 데이터는 반드시 data buffer cache에 존재해야 합니다.
(없으면 disk에서 읽어옴)
Data buffer cache를 사용하는 이유는 데이터는 data file, 즉 디스크에 저장이 되는데
사용자가 데이터를 가져오려고 할 때 마다 디스크에서 가져오면 속도가 정말 느리겠죠?
그래서 자주 쓰이는 데이터, 필요한 데이터 등을 data buffer cache에 올려놓고 사용합니다.
- Redo log buffer
데이터에 변경사항이 생길 경우 해당 변경 내용을 기록해 두는 역할을 합니다.
앞으로 다룰 내용인 오라클 백업&복구에서 매우 중요한 역할을 하는 구성요소로서
redo log는 영수증과 같다고 보시면 됩니다.
매장 (Oracle) 에서 물건을 산 뒤 (DDL,DML) 물건의 하자 등의 이유로 교환이나 환불을 원할 때 (Recovery)
매장 측에선 영수증 (redo log) 를 보고 해당 물건과 값에 대해 처리를 해주는 것이죠.
- Shared pool
Shared pool은 하나의 데이터베이스에서 수행되는 모든 쿼리를 처리하기 위해 사용됩니다.
Library cache는 이미 수행 되었던 쿼리에 대한 실행계획,쿼리문장 등이 저장 되어 있어서
만약 여러 명의 사용자가 같은 쿼리를 수행하는 경우
library cache에서 해당 쿼리에 대한 실행 계획 등을 공유하기 때문에 자원을 절약할 수 있습니다.
Dictionary cache에서는 데이터베이스 내 오브젝트, 사용자등에 대한 정보가 저장 되어 있어서
쿼리에 대해 syntax check, semantic check를 수행 할 때 사용됩니다.
백그라운드 프로세스
1) DBWR 2) LGWR 3) PMON 4) SMON 5) CKPT
파일 영역
1) 파라미터 파일 – Instance를 어떻게 설계할지 정보가 담겨져 있는 파일 (initORACLE_SID.ora)
2) 컨트롤파일 – Database 전체의 정보를 갖고 있는 파일
3) 데이터파일 – 실제 테이블들의 데이터 등의 정보가 기록 되는 파일
4) 리두로그파일 – 오라클의 모든 변경사항이 기록되는 파일
쿼리수행
SELECT 문이 어떻게 수행되는지 간단히 살펴보면서 위에서 본 개념들이 어떻게 사용되는지 알아보겠습니다.
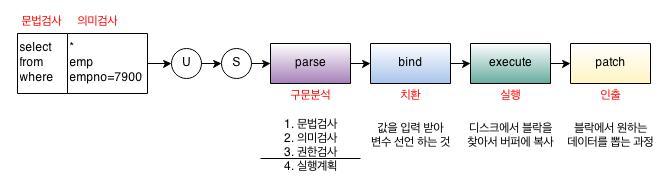
client 사용자는 User Process (sql plus, orange,toad,oracle client 등)을 통해 SQL문장을 DB서버로 보냅니다.
DB 서버에는 Listener라는 프로그램이 있는데

이 listener가 사용자의 접속 요청을 확인하고 조건을 만족하면
Server process와 User Process (사용자)를 맺어주게 되고 이 Server process를 통해서 DB에서 쿼리를 수행하게 됩니다.
- PARSE
그 후 쿼리는 SGA의 parse 라는 단계를 거칩니다.
이 때 Shared pool에서 syntax, semantic check 검사를 하는데
ERROR at line 2:
ORA-00942: table or view does not exist
ERROR at line 2:
ORA-00923: FROM keyword not found where expected
문법이 맞는지, 조회하려는 테이블이 실제로 존재하는지에 대한 검사를 parsing 단계에서 하게 됩니다.
그리고 실행계획을 생성하게 되는데 shared pool에는 수행 했던 쿼리들에 대한 실행계획을 갖고 있어서
실행계획이 존재하면
soft parsing-> 기존의 실행계획 재사용
존재하지 않으면
hard parsing->optimizer
단계를 추가로 거쳐 실행계획 생성 을 하게 됩니다.
- Bind
bind 단계는 효율성을 위해 꼭 필요한 단계라고 할 수 있습니다.
binding의 개념이 없다면 100명의 학생이 영어점수를 조회하려고 하면
같은 테이블의 같은 컬럼을 조회하고 학번과 이름만 다른 실행계획이 100개 생길 것 입니다.
학번과 이름을 bind 변수로 지정하면
실행계획은 1개만 생성후 100번 실행해 hard parsing하는 리소스를 절약할 수 있습니다.
- execute
실행단계는 필요한 데이터를 data buffer cache로 가져옵니다.
데이터가 없으면 위에서 언급했듯이 DISK (data file)에서 필요한 data를 가져오는데
느린 disk에서 빠른 메모리로 옮기는 과정이다 보니 병목현상이 많이 생기기도 합니다.
- Fetch
execute 과정에서 data buffer cache로 가져온 데이터를 사용자에게 전달해 주는 과정입니다.
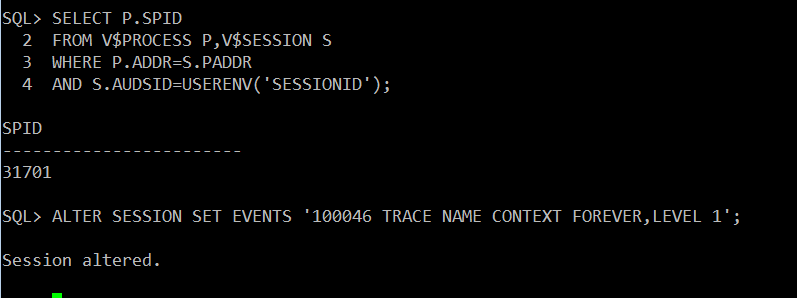
내 쿼리가 hard parsing 되는지 soft parsing 되는지 확인하는 방법
- 현재 자신의 spid 확인 및 10046 trace 걸기
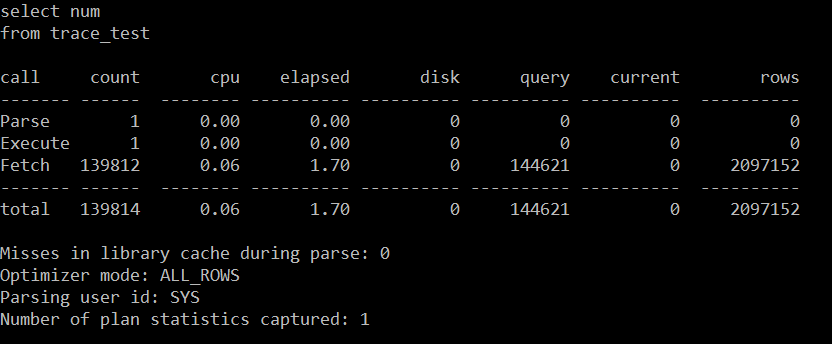
- 처음 쿼리 수행 후 trace 결과 화면
( Select num from trace_test 쿼리 수행 뒤 10046 trace 결과 화면 )
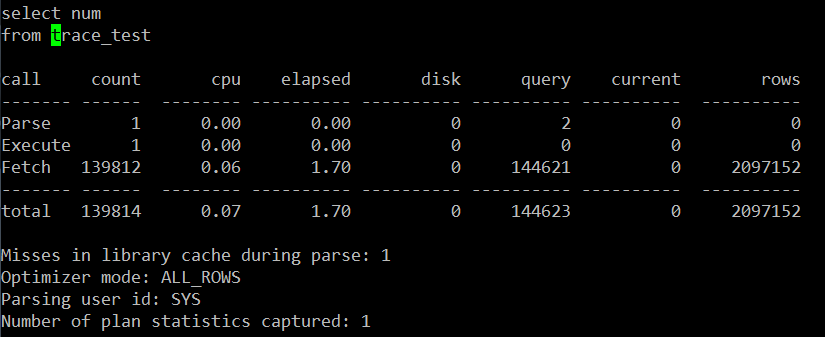
위에서
Misses in library cache during parse : 1
1은 hard parsing 을 의미 합니다.
- 같은 쿼리 수행 후 trace 결과 화면
( Select num from trace_test 재수행 뒤 10046 trace 결과 )
위에서
Misses in library cache during parse : 0
0은 soft parsing을 의미합니다
오라클 기동 단계
- NOMOUNT
nomount 단계에서는 initORACLE\_SID.ora 파라미터파일을 바탕으로 인스턴스 (SGA+Background process) 를 생성합니다. 그렇기 때문에 parameter file을 바탕으로 한 아래와 같은 정보만 조회 할 수 있습니다.
select * from v$instance;
select * from v$parameter;
select * from v$version;
show sga;
- MOUNT
Mount 단계에서는 instance와 Database 가 맞춰지는 단계로 모든 상태 정보를 읽어오게 됩니다.
control file을 읽어서 데이터 파일이나 리두 로그 파일등의 위치와 상태만 알 뿐 실제 물리적인 파일이 열린 상태는 아닙니다.
select status from v$instance; ==> (status => mounted)
select * from v$database;
select * from v$datafile;
select * from v$controlfile;
select * from v$logfile;
- OPEN
Open 단계에서는 컨트롤파일에서 읽은 DATA FILE 이나 ONLINE REDO LOG FILE 의 위치 및 OPEN 가능여부를 확인하고 데이터 베이스 일관성을 검사합니다.
여기서 말하는 일관성이란
모든 데이터 파일과 컨트롤 파일들이 같은 시점의 데이터들 인지 검증하기 위해 SCN을 비교하는 과정으로 recovery가 필요한지 불필요한지를 결정하는 중요한 단계라고 할 수 있습니다.