2년전에 citus가 어떤 것인지 궁금해서 구성 관련 간단히 테스트했던 내용입니다.
깊이있는 내용은 전혀 아니고 지금 다시 읽어보니 거의 저만 이해할 수 있게 써놨네요…..
현재는 citus나 postgresql 버전이 테스트 당시와 상이할 수 있어 틀린 내용이 많을 수 있습니다.
목차
- Citus 란?
- HA 방식에 따른 아키텍처
- 성능 테스트
- Citus 설치 방법
- Query processing
- Distributed deadlock
- Query plan
- 참고 내용
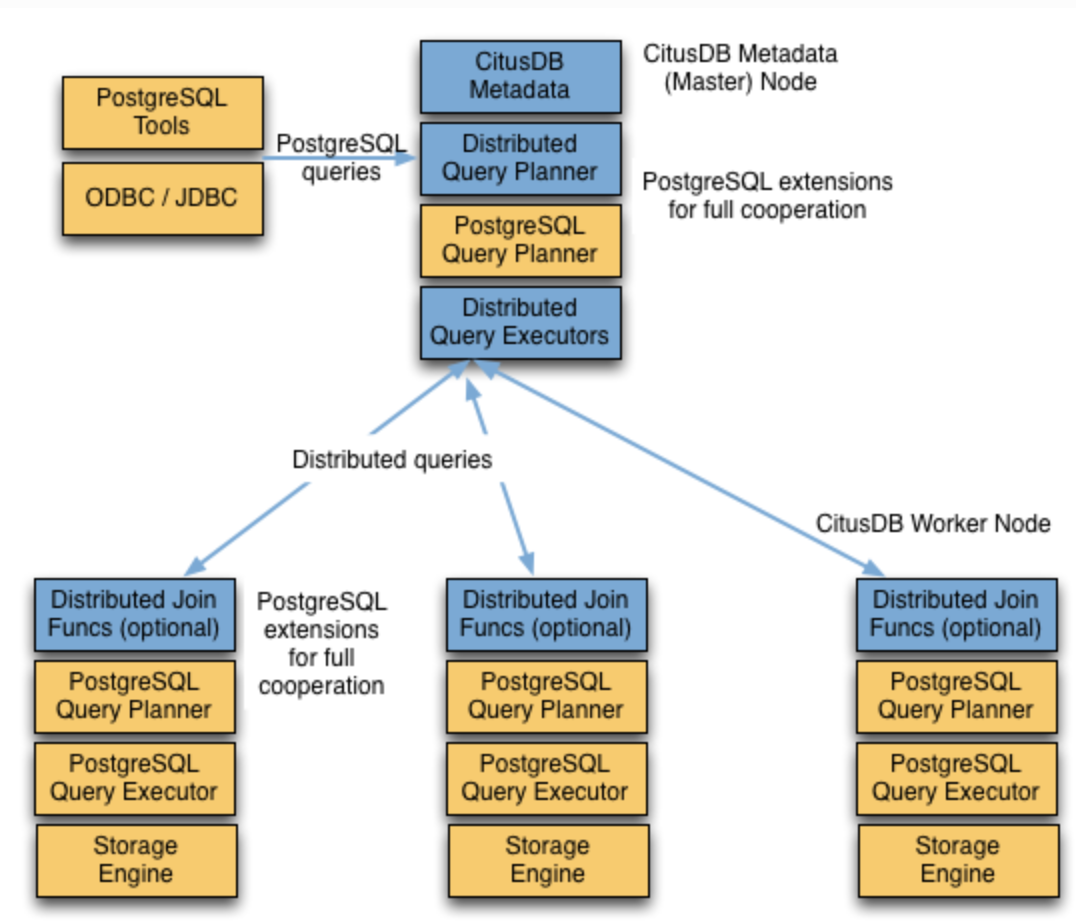
Citus
-. PostgreSQL 의 scale-out 용도 extension ( mysql plugin )
-. hash 기반으로 테이블을 분산함
-. 엔터프라이즈 버전은 자동 리밸런싱 + 커넥션 풀 지원
-. node 간 HA 별도 구축 필요 -. 별도의 백업정책 필요함
-. mongodb sharding + mysql spider engine 아키텍처와 유사

coordinator : distributed table에 대한 meta data 관리, 클라이언트의 요청을 워커노드에 전달하는 역할
* query 최종 sorting 작업 수행
worker node : coordinator로 부터 요청을 받아 실제 데이터를 처리한 후 coordinator 에게 전달하는 역할
* dml, ddl, analyze, vacuum 등 coordinator 로 부터 전달 받은 커맨드 실행
HA 방식에 따른 아키텍처
shard_replication_factor
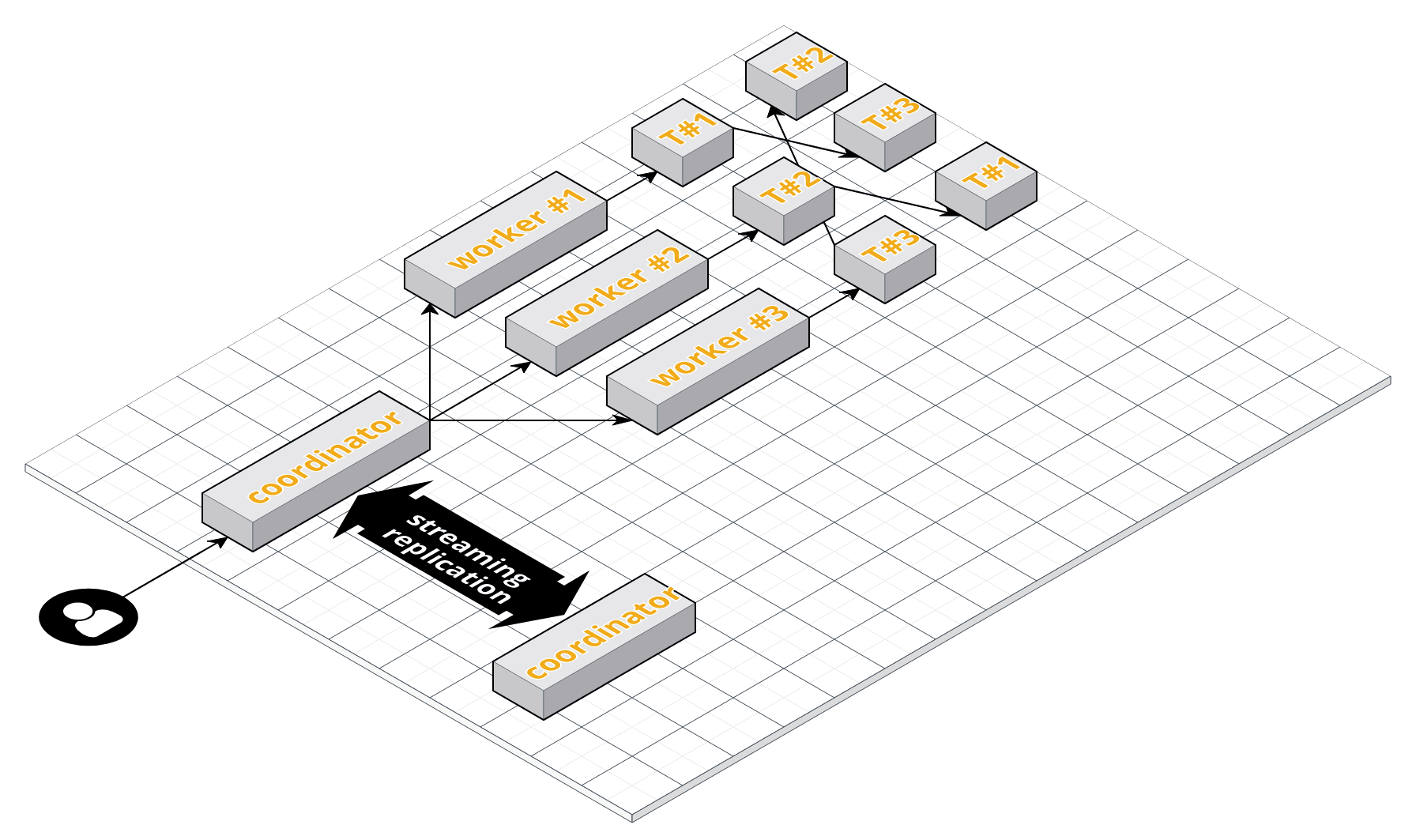
=> worker node down 에 대비하여 분산 테이블을 다른 worker node에도 복제하는 방식
구축은 쉬우나 worker node down 시 일부 dml 불가 현상 및 수동으로 sync 맞춰줘야 하는 단점이 있음replication + pgpool+master_add_secondary_node
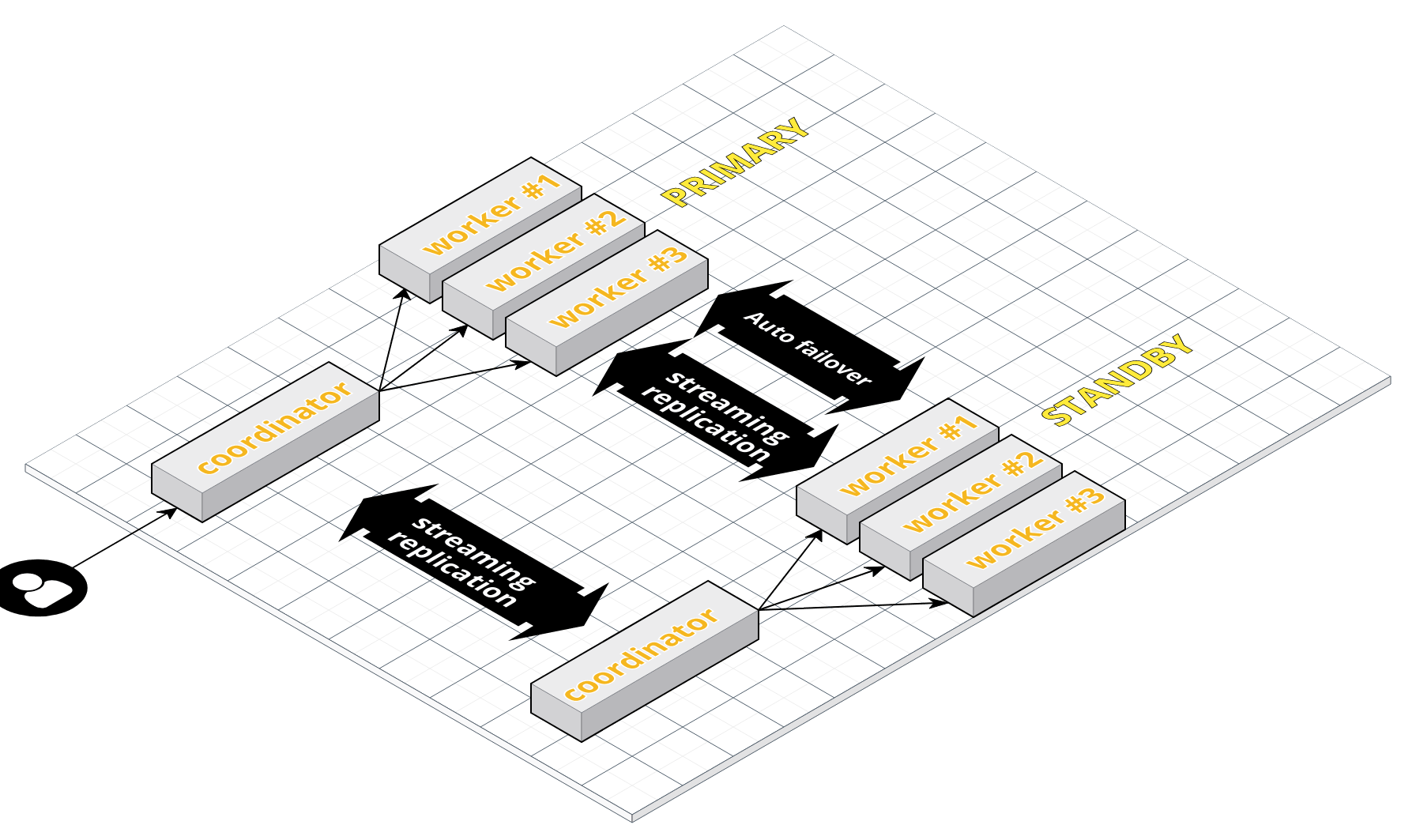
=> Primary node down 시 auto-failover 된 standby node가 투입되는 방식streaming replication : postgresql 의 복제 방식으로 mysql처럼 sql thread /io thread 방식과 유사함 (PostgreSQL에서는 sender / receiver, sql 커맨드 대신 트랜잭션로그)
pgpool : auto - failover
성능 테스트
single node와 citus - 3 worker nodes 아키텍처 (azure) 간 성능 테스트
data load
- single
citus=> \copy github_events FROM large_events.csv with csv
COPY 1146625
Time: 1451256.144 ms (24:11.256)
- citus
citus=> \copy github_events from 'large_events.csv' with csv;
COPY 1146625
Time: 879733.291 ms (14:39.733)
index 생성
- single
citus=> create index test_idx on github_events using gin(payload jsonb_path_ops);
CREATE INDEX
Time: 193734.521 ms (03:13.735)
- citus
citus=> create index test_idx on github_events using gin(payload jsonb_path_ops);
CREATE INDEX
Time: 49713.177 ms (00:49.713)
select
- single
SELECT date_trunc('minute', created_at) AS minute,
sum((payload->>'distinct_size')::int) AS num_commits
FROM github_events
WHERE event_type = 'PushEvent'
GROUP BY minute
ORDER BY minute;
Time: 1213.770 ms (00:01.214)
- citus
SELECT date_trunc('minute', created_at) AS minute,
sum((payload->>'distinct_size')::int) AS num_commits
FROM github_events
WHERE event_type = 'PushEvent'
GROUP BY minute
ORDER BY minute;
Time: 847.792 ms
구성 방법
모든 노드에 citus 설치
docker network create citus-test
docker run --name citus_master -d --network citus-test citusdata/citus
docker run --name citus_slave -d --network citus-test citusdata/citus
docker run --name citus_worker1 -d --network citus-test citusdata/citus
docker run --name citus_worker2 -d --network citus-test citusdata/citus
docker run --name citus_worker3 -d --network citus-test citusdata/citus
docker run --name citus_worker1_standby -d --network citus-test citusdata/citus
docker run --name citus_worker2_standby -d --network citus-test citusdata/citus
docker run --name citus_worker3_standby -d --network citus-test citusdata/citus
=> primary worker node 3대 + standby worker node 3대 + coordinator M/S 하나씩
streaming replication + pgpool 로 HA 구성
postgres=# select * from pg_available_extensions where name='citus';
name | default_version | installed_version | comment
-------+-----------------+-------------------+----------------------------
citus | 8.3-1 | 8.3-1 | Citus distributed database
(1 row)
=> citus extension 설치 (extension 은 mysql 의 plugin 개념)
pg_hba.conf 에 노드 추가
postgres@07a3ccbd0898:~/data$ tail -5f pg_hba.conf
host replication all 172.19.0.0/24 trust
host all all 172.19.0.0/24 trust
postgres@07a3ccbd0898:~$ /usr/lib/postgresql/11/bin/pg_ctl reload -D /var/lib/postgresql/data
server signaled
=> oracle 의 sqlnet.ora, cubrid iplist , mysql ip/host 개념처럼 해당 db에 붙을 수 있는 host 허용하는 부분
coordinator node 에 워커노드 추가하기
postgres=# SELECT master_add_node ('citus_worker1',5432);
master_add_node
------------------------------------------------------
(7,7,citus_worker1,5432,default,f,t,primary,default)
(1 row)
postgres=# SELECT master_add_node ('citus_worker2',5432);
master_add_node
------------------------------------------------------
(8,8,citus_worker2,5432,default,f,t,primary,default)
(1 row)
postgres=# SELECT master_add_node ('citus_worker3',5432);
master_add_node
------------------------------------------------------
(9,9,citus_worker3,5432,default,f,t,primary,default)
(1 row)
postgres=# select master_add_secondary_node('citus_worker1_standby','5432','citus_worker1','5432');
master_add_secondary_node
-----------------------------------------------------------------
(10,7,citus_worker1_standby,5432,default,f,t,secondary,default)
(1 row)
postgres=# select master_add_secondary_node('citus_worker2_standby','5432','citus_worker2','5432');
master_add_secondary_node
-----------------------------------------------------------------
(10,7,citus_worker2_standby,5432,default,f,t,secondary,default)
(1 row)
postgres=# select master_add_secondary_node('citus_worker3_standby','5432','citus_worker3','5432');
master_add_secondary_node
-----------------------------------------------------------------
(10,7,citus_worker3_standby,5432,default,f,t,secondary,default)
(1 row)
=> hostname,port 로 worker node, standby worker node 추가
추가된 워커노드 확인
postgres=# select * from pg_dist_node;
nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster
--------+---------+-----------------------+----------+----------+-------------+----------+-----------+-------------
7 | 7 | citus_worker1 | 5432 | default | f | t | primary | default
8 | 8 | citus_worker2 | 5432 | default | f | t | primary | default
9 | 9 | citus_worker3 | 5432 | default | f | t | primary | default
10 | 7 | citus_worker1_standby | 5432 | default | f | t | secondary | default
11 | 8 | citus_worker2_standby | 5432 | default | f | t | secondary | default
12 | 9 | citus_worker3_standby | 5432 | default | f | t | secondary | default
(6 rows)
distributed table 생성
- citus coordinator 에서 수행
postgres=# set citus.shard_count=6;
SET
# shard_replication_factor 사용할 땐 아래 설정 추가
postgres=# set citus.shard_replication_factor=2;
SET
- citus.shard_count : 해당 테이블을 몇개로 쪼갤 것인지 설정 (default 32)
- citus.shard_replication_factor : 쪼개진 테이블의 복사본을 몇개 갖고 있을 것인지 설정 (default 1)
- ( shard_count 6 * replication_factor 2 ) / worker node 3 = 4 => 한 노드에 쪼개진 테이블 4개씩 갖고있게됨
CREATE TABLE companies (
id bigint NOT NULL,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigint NOT NULL,
company_id bigint NOT NULL,
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blacklisted_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE ads (
id bigint NOT NULL,
company_id bigint NOT NULL,
campaign_id bigint NOT NULL,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
=> test 용 테이블 생성
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
=> 생성한 테이블을 각각 id, company_id, company_id 기준으로 distributed table 생성
coordinator
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | ads | table | postgres
public | campaigns | table | postgres
public | companies | table | postgres
- worker node 1
public | campaigns_102174 | table | postgres
public | campaigns_102176 | table | postgres
public | campaigns_102178 | table | postgres
- worker node 2
public | campaigns_102175 | table | postgres
public | campaigns_102177 | table | postgres
public | campaigns_102179 | table | postgres
postgres=# select a.logicalrelid,a.shardid,a.shardminvalue,a.shardmaxvalue,b.shardstate,b.groupid
from pg_dist_shard a inner join pg_dist_placement b on a.shardid=b.shardid
where a.logicalrelid=CAST('campaigns' as regclass);
logicalrelid | shardid | shardminvalue | shardmaxvalue | shardstate | groupid
--------------+---------+---------------+---------------+------------+---------
campaigns | 102174 | -2147483648 | -1431655767 | 1 | 1
campaigns | 102175 | -1431655766 | -715827885 | 1 | 2
campaigns | 102176 | -715827884 | -3 | 1 | 1
campaigns | 102177 | -2 | 715827879 | 1 | 2
campaigns | 102178 | 715827880 | 1431655761 | 1 | 1
campaigns | 102179 | 1431655762 | 2147483647 | 1 | 2
=> 생성된 distributed table 과 매핑되는 hash value range
Query processiong 과정
postgres=# SELECT master_get_table_metadata('test');
master_get_table_metadata
------------------------------
(16759,t,h,t,1,1073741824,2)
(1 row)
postgres=#select * From pg_backend_pid();
pg_backend_pid
----------------
796
(1 row)
postgres=# select * from test;
=> 디버깅 대상 세션 준비
[root@1a99d5cd2d41 /]# gdb -p 796
(gdb) b CreateDistributedPlan
Breakpoint 1 at 0x7fc3a0bf9e20: file planner/distributed_planner.c, line 575.
(gdb) b ExecProcNode
Breakpoint 2 at 0x5f3225: ExecProcNode. (55 locations)
(gdb) b IsDistributedTable
Breakpoint 3 at 0x7fc3a0c25560: file utils/metadata_cache.c, line 269.
(gdb) b CitusExecutorRun
Breakpoint 4 at 0x7fc3a0be9580: file executor/multi_executor.c, line 108.
(gdb) b CitusExecutorStart
Breakpoint 5 at 0x7fc3a0be9480: file executor/multi_executor.c, line 64.
=> gdb breakpoint 설정
Breakpoint 3, IsDistributedTable (relationId=16759) at utils/metadata_cache.c:269
269 {
(gdb) bt
#0 IsDistributedTable (relationId=16759) at utils/metadata_cache.c:269
#1 0x00007fc3a0bf9963 in ListContainsDistributedTableRTE (rangeTableList=rangeTableList@entry=0x1961150)
at planner/distributed_planner.c:289
#2 0x00007fc3a0bfa525 in distributed_planner (parse=0x1960a68, cursorOptions=256, boundParams=0x0)
at planner/distributed_planner.c:117
#3 0x00000000007261fc in pg_plan_query (querytree=querytree@entry=0x1960a68, cursorOptions=cursorOptions@entry=256,
boundParams=boundParams@entry=0x0) at postgres.c:832
#4 0x00000000007262de in pg_plan_queries (querytrees=<optimized out>, cursorOptions=cursorOptions@entry=256,
boundParams=boundParams@entry=0x0) at postgres.c:898
#5 0x000000000072674a in exec_simple_query (query_string=0x195fc10 "select * from test;") at postgres.c:1073
#6 0x00000000007278c2 in PostgresMain (argc=<optimized out>, argv=argv@entry=0x19b2480, dbname=0x19b2328 "postgres",
username=<optimized out>) at postgres.c:4182
#7 0x000000000047b0cf in BackendRun (port=0x19aa6c0) at postmaster.c:4358
#8 BackendStartup (port=0x19aa6c0) at postmaster.c:4030
#9 ServerLoop () at postmaster.c:1707
#10 0x00000000006be989 in PostmasterMain (argc=argc@entry=3, argv=argv@entry=0x195b960) at postmaster.c:1380
#11 0x000000000047bb11 in main (argc=3, argv=0x195b960) at main.c:228
=> “select * from test” parsing 후 distributed_planner 에서 해당 테이블이 distributed table인지 check ((relationId=16759)
Breakpoint 3, IsDistributedTable (relationId=16759) at utils/metadata_cache.c:269
269 {
(gdb) bt
#0 CreateDistributedPlan (planId=planId@entry=5, originalQuery=originalQuery@entry=0x1960958, query=query@entry=0x1960a68,
boundParams=boundParams@entry=0x0, hasUnresolvedParams=hasUnresolvedParams@entry=false,
plannerRestrictionContext=plannerRestrictionContext@entry=0x1961608) at planner/distributed_planner.c:575
#1 0x00007fc3a0bfa34d in CreateDistributedPlannedStmt (plannerRestrictionContext=0x1961608, boundParams=0x0, query=0x1960a68,
originalQuery=0x1960958, localPlan=0x19af2c0, planId=5) at planner/distributed_planner.c:493
#2 distributed_planner (parse=0x1960a68, cursorOptions=256, boundParams=0x0) at planner/distributed_planner.c:185
=> distributed plan 생성 시작
Breakpoint 3, IsDistributedTable (relationId=16759) at utils/metadata_cache.c:269
269 {
(gdb) bt
#0 IsDistributedTable (relationId=relationId@entry=16759) at utils/metadata_cache.c:269
#1 0x00007fc3a0c0a771 in MultiRouterPlannableQuery (query=query@entry=0x1960a68) at planner/multi_router_planner.c:3002
#2 0x00007fc3a0c0cc61 in CreateRouterPlan (originalQuery=originalQuery@entry=0x1960958, query=query@entry=0x1960a68,
plannerRestrictionContext=plannerRestrictionContext@entry=0x1961608) at planner/multi_router_planner.c:179
#3 0x00007fc3a0bf9ebe in CreateDistributedPlan (planId=planId@entry=5, originalQuery=originalQuery@entry=0x1960958,
query=query@entry=0x1960a68, boundParams=boundParams@entry=0x0, hasUnresolvedParams=hasUnresolvedParams@entry=false,
plannerRestrictionContext=plannerRestrictionContext@entry=0x1961608) at planner/distributed_planner.c:632
#4 0x00007fc3a0bfa34d in CreateDistributedPlannedStmt (plannerRestrictionContext=0x1961608, boundParams=0x0, query=0x1960a68,
originalQuery=0x1960958, localPlan=0x19af2c0, planId=5) at planner/distributed_planner.c:493
#5 distributed_planner (parse=0x1960a68, cursorOptions=256, boundParams=0x0) at planner/distributed_planner.c:185
=> 어떤 worker node로 보낼지 plan 생성
Breakpoint 5, CitusExecutorStart (queryDesc=0x1a78a20, eflags=0) at executor/multi_executor.c:64
64 {
(gdb) bt
#0 CitusExecutorStart (queryDesc=0x1a78a20, eflags=0) at executor/multi_executor.c:64
=> 생성된 distributed plan 을 worker node에서 실행시킬 준비
Breakpoint 4, CitusExecutorRun (queryDesc=0x1a78a20, direction=ForwardScanDirection, count=0, execute_once=true)
at executor/multi_executor.c:108
108 {
(gdb) bt
#0 CitusExecutorRun (queryDesc=0x1a78a20, direction=ForwardScanDirection, count=0, execute_once=true)
at executor/multi_executor.c:108
Breakpoint 2, ExecutePlan (execute_once=<optimized out>, dest=0x1b0d4d0, direction=ForwardScanDirection, numberTuples=0,
sendTuples=true, operation=CMD_SELECT, use_parallel_mode=<optimized out>, planstate=0x1a717c0, estate=0x1a715b0)
at execMain.c:1723
1723 slot = ExecProcNode(planstate);
(gdb) bt
#0 ExecutePlan (execute_once=<optimized out>, dest=0x1b0d4d0, direction=ForwardScanDirection, numberTuples=0, sendTuples=true,
operation=CMD_SELECT, use_parallel_mode=<optimized out>, planstate=0x1a717c0, estate=0x1a715b0) at execMain.c:1723
#1 standard_ExecutorRun (queryDesc=queryDesc@entry=0x1a78a20, direction=direction@entry=ForwardScanDirection,
count=count@entry=0, execute_once=execute_once@entry=true) at execMain.c:364
#2 0x00007fc3a0be95d3 in CitusExecutorRun (queryDesc=0x1a78a20, direction=ForwardScanDirection, count=0,
execute_once=<optimized out>) at executor/multi_executor.c:151
=> 각각의 worker node 에서 query 수행
Distributed Deadlock
coordinator
| session 1 | session 2 |
| --- | --- |
| update test set b='session1' where a=1;| |
| | update test set b='session2' where a=2; |
| update test set b='session1' where a=2; | |
| | update test set b='session2' where a=1; |
worker node 관점
| worker1 | | worker2 | |
| --- | --- | --- | --- |
| update test_worker1 set b='session1' where a=1; | holder | update test_worker2 set b='session2' where a=2; | holder |
| update test_worker1 set b='session2' where a=1; | waiter | update test_worker2 set b='session1' where a=2; | waiter |
=> 각 worker node가 봤을 때는 단순한 lock 대기상황
coordinator 관점
=> session1의 트랜잭션은 worker node2 에서 session2 에 의해 대기,
session2 의 트랜잭션은 worker node1 에서 session1 에 의해 대기하는 deadlock 상황
* session 1 (1,1)
(gdb) info locals
currentDistributedTransactionId = 0x10b5340
backendData = {databaseId = 12368, userId = 10, mutex = 1 '\001', cancelledDueToDeadlock = false, citusBackend = {initiatorNodeIdentifier = 0, transactionOriginator = true},
transactionId = {initiatorNodeIdentifier = 0, transactionOriginator = true, transactionNumber = 16, timestamp = 622787261936074}}
* session 2 (2,2)
currentDistributedTransactionId = 0x10c0340
backendData = {databaseId = 12368, userId = 10, mutex = 1 '\001', cancelledDueToDeadlock = true, citusBackend = {initiatorNodeIdentifier = 0, transactionOriginator = true}, transactionId = {
initiatorNodeIdentifier = 0, transactionOriginator = true, transactionNumber = 17, timestamp = 622787449815181}}
* session 1 (1,2)
currentDistributedTransactionId = 0x10b5340
backendData = {databaseId = 12368, userId = 10, mutex = 1 '\001', cancelledDueToDeadlock = false, citusBackend = {initiatorNodeIdentifier = 0, transactionOriginator = true},
transactionId = {initiatorNodeIdentifier = 0, transactionOriginator = true, transactionNumber = 16, timestamp = 622787261936074}}
* session 2 (2,1)
(gdb) info locals
currentDistributedTransactionId = 0x10c0340
backendData = {databaseId = 12368, userId = 10, mutex = 1 '\001', cancelledDueToDeadlock = true, citusBackend = {initiatorNodeIdentifier = 0, transactionOriginator = true}, transactionId = {
initiatorNodeIdentifier = 0, transactionOriginator = true, transactionNumber = 17, timestamp = 622787449815181}}
=> deadlock 발생구간에서 트랜잭션ID 가 큰 후순위 트랜잭션을 kill 해서 deadlock 처리함
쿼리 실행계획
distributed table 간 JOIN
set citus.explain_all_tasks = on ;
SELECT campaigns.id, campaigns.name, campaigns.monthly_budget,
sum(impressions_count) as total_impressions, sum(clicks_count) as total_clicks
FROM ads, campaigns
WHERE ads.company_id = campaigns.company_id
AND campaigns.company_id=5
AND campaigns.state = 'running'
GROUP BY campaigns.id, campaigns.name, campaigns.monthly_budget
ORDER BY total_impressions, total_clicks;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=citus_worker3 port=5432 dbname=postgres
-> Sort (cost=49.87..49.88 rows=3 width=94)
Sort Key: (sum(ads.impressions_count)), (sum(ads.clicks_count))
-> HashAggregate (cost=49.81..49.85 rows=3 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Nested Loop (cost=0.00..46.54 rows=261 width=46)
-> Seq Scan on ads_102021 ads (cost=0.00..38.04 rows=87 width=24)
Filter: (company_id = 5)
-> Materialize (cost=0.00..5.25 rows=3 width=38)
-> Seq Scan on campaigns_102015 campaigns (cost=0.00..5.23 rows=3 width=38)
Filter: ((company_id = 5) AND (state = 'running'::text))
- 두 테이블 간 조인을 하는데 citus_worker3 한 노드에서만 데이터를 가져옴
- 동일한 distributed column ( company_id =5 )에 대해서는 어차피 해쉬값이 같기 때문에 한노드에 저장됨
- 명시적으로는 아래와 같이 설정 가능
- SELECT create_distributed_table(‘event’, ‘tenant_id’);
- SELECT create_distributed_table(‘page’, ‘tenant_id’, colocate_with => ‘event’);
SELECT campaigns.id, campaigns.name, campaigns.monthly_budget,
sum(impressions_count) as total_impressions, sum(clicks_count) as total_clicks
FROM ads, campaigns
WHERE ads.company_id = campaigns.company_id
AND campaigns.company_id between 1 and 100
AND campaigns.state = 'running'
GROUP BY campaigns.id, campaigns.name, campaigns.monthly_budget
ORDER BY total_impressions, total_clicks;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: pg_catalog.sum((pg_catalog.sum(remote_scan.total_impressions))), pg_catalog.sum((pg_catalog.sum(remote_scan.total_clicks)))
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.id, remote_scan.name, remote_scan.monthly_budget
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 6
Tasks Shown: All
-> Task
Node: host=citus_worker1 port=5432 dbname=postgres
-> HashAggregate (cost=185.41..186.35 rows=63 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=58.58..123.37 rows=4963 width=46)
Hash Cond: (campaigns.company_id = ads.company_id)
-> Seq Scan on campaigns_102014 campaigns (cost=0.00..6.19 rows=63 width=38)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Hash (cost=41.59..41.59 rows=1359 width=24)
-> Seq Scan on ads_102020 ads (cost=0.00..41.59 rows=1359 width=24)
-> Task
Node: host=citus_worker2 port=5432 dbname=postgres
-> HashAggregate (cost=136.52..137.12 rows=40 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=49.27..94.11 rows=3393 width=46)
Hash Cond: (campaigns.company_id = ads.company_id)
-> Seq Scan on campaigns_102015 campaigns (cost=0.00..5.61 rows=40 width=38)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Hash (cost=35.23..35.23 rows=1123 width=24)
-> Seq Scan on ads_102021 ads (cost=0.00..35.23 rows=1123 width=24)
-> Task
Node: host=citus_worker3 port=5432 dbname=postgres
-> HashAggregate (cost=161.65..162.44 rows=53 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=49.67..106.97 rows=4374 width=46)
Hash Cond: (campaigns.company_id = ads.company_id)
-> Seq Scan on campaigns_102016 campaigns (cost=0.00..5.68 rows=53 width=38)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Hash (cost=35.41..35.41 rows=1141 width=24)
-> Seq Scan on ads_102022 ads (cost=0.00..35.41 rows=1141 width=24)
-> Task
Node: host=citus_worker1 port=5432 dbname=postgres
-> HashAggregate (cost=156.06..156.83 rows=51 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=47.91..103.41 rows=4212 width=46)
Hash Cond: (campaigns.company_id = ads.company_id)
-> Seq Scan on campaigns_102017 campaigns (cost=0.00..5.61 rows=51 width=38)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Hash (cost=34.07..34.07 rows=1107 width=24)
-> Seq Scan on ads_102023 ads (cost=0.00..34.07 rows=1107 width=24)
-> Task
Node: host=citus_worker2 port=5432 dbname=postgres
-> HashAggregate (cost=161.72..162.56 rows=56 width=95)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=6.13..103.98 rows=4619 width=47)
Hash Cond: (ads.company_id = campaigns.company_id)
-> Seq Scan on ads_102024 ads (cost=0.00..31.22 rows=1022 width=24)
-> Hash (cost=5.43..5.43 rows=56 width=39)
-> Seq Scan on campaigns_102018 campaigns (cost=0.00..5.43 rows=56 width=39)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Task
Node: host=citus_worker3 port=5432 dbname=postgres
-> HashAggregate (cost=215.04..216.08 rows=69 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Hash Join (cost=70.27..144.78 rows=5621 width=46)
Hash Cond: (campaigns.company_id = ads.company_id)
-> Seq Scan on campaigns_102019 campaigns (cost=0.00..7.61 rows=69 width=38)
Filter: ((company_id >= 1) AND (company_id <= 100) AND (state = 'running'::text))
-> Hash (cost=50.12..50.12 rows=1612 width=24)
-> Seq Scan on ads_102025 ads (cost=0.00..50.12 rows=1612 width=24)
- company_id 조건을 between 범위검색으로 변경
- company_id =5 일 때 target query 로 처리되었던 것과는 달리 broad cast 로 모든 worker node 사용하게 됨
- 각각의 worker_node 에서 데이터 추출 후 최종적으로 coordinator에서 취합 & sorting 수행
- mongodb 에서는 shard node 간 primary 선출, sorting 후 mongus 로 return 하는 것과는 달리 coordinator 에서 더 많은 역할을 수행함
distributed table 과 local table 간 JOIN
SELECT campaigns.id, campaigns.name, campaigns.monthly_budget,
sum(impressions_count) as total_impressions, sum(clicks_count) as total_clicks
FROM local_ads ads, campaigns
WHERE ads.company_id = campaigns.company_id
AND campaigns.company_id=5
AND campaigns.state = 'running'
GROUP BY campaigns.id, campaigns.name, campaigns.monthly_budget
ORDER BY total_impressions, total_clicks;
ERROR: relation local_ads is not distributed
=> local table , 분산되지 않은 일반 테이블은 distributed table 과 조인이 불가능함.
아래와 같이 inline view 로 풀어서 수행
SELECT campaigns.id, campaigns.name, campaigns.monthly_budget,
sum(impressions_count) as total_impressions, sum(clicks_count) as total_clicks
FROM (select * from local_ads) ads, campaigns
WHERE ads.company_id = campaigns.company_id
AND campaigns.company_id=5
AND campaigns.state = 'running'
GROUP BY campaigns.id, campaigns.name, campaigns.monthly_budget
ORDER BY total_impressions, total_clicks;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 3_1
-> Seq Scan on local_ads (cost=0.00..225.64 rows=7364 width=134)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=citus_worker2 port=5432 dbname=postgres
-> Sort (cost=18.19..18.20 rows=3 width=94)
Sort Key: (sum(intermediate_result.impressions_count)), (sum(intermediate_result.clicks_count))
-> HashAggregate (cost=18.12..18.17 rows=3 width=94)
Group Key: campaigns.id, campaigns.name, campaigns.monthly_budget
-> Nested Loop (cost=0.00..17.93 rows=15 width=46)
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..12.50 rows=5 width=24)
Filter: (company_id = 5)
-> Materialize (cost=0.00..5.25 rows=3 width=38)
-> Seq Scan on campaigns_102015 campaigns (cost=0.00..5.23 rows=3 width=38)
Filter: ((company_id = 5) AND (state = 'running'::text))