시작하며
PostgreSQL의 background process는 기본 프로세스인 Postmaster에서 fork() 된 프로세스들입니다.
각 fork() 된 background process들은 DBMS 운영을 위해 각자 맡은 역할을 수행하게 되는데요.
지난 글에서 PostgreSQL의 architecture에 대해 살펴보며 간략하게 말씀드렸지만
이번 글에서는 PostgreSQL의 background process들에 대해 좀 더 자세히 살펴보겠습니다.
PostgreSQL background process
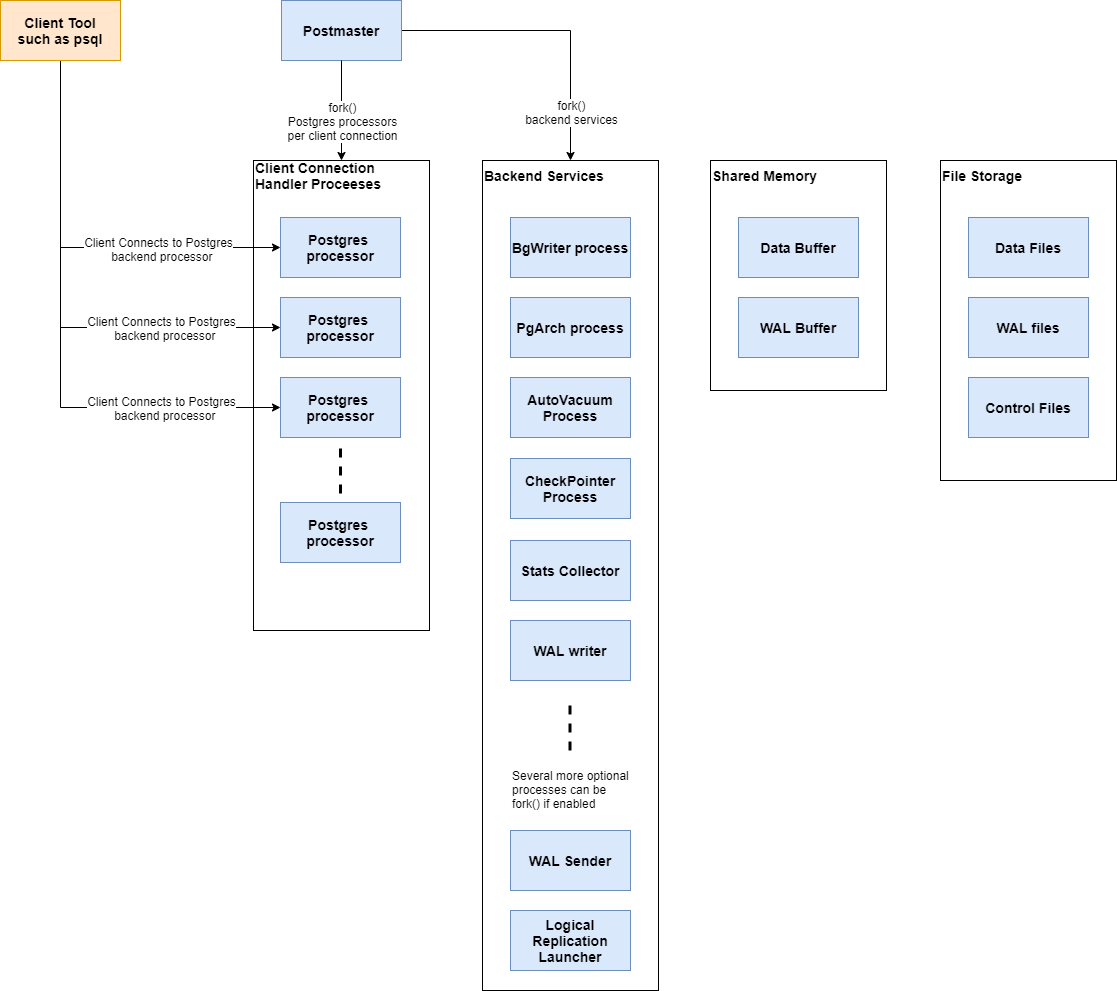
Postmaster
Postmaster 는 모든 background process들을 제어하고 client => DBMS로의 connection을 생성하고 닫아주는 최초의 프로세스입니다.
- DB 기동 시 Postmaster는 다른 background process를 fork() 하는 역할과
- client가 PostgreSQL DBMS에 connection을 요청하면 Postmaster는 설정된 인증방법(pg_hba.conf)에 따라 사용자를 인증하고
인증을 통과하면 사용자에게 서비스를 제공하기 위한 새로운 session을 fork() 하는 역할을 합니다.
BgWriter
BgWriter 프로세스는 Shared Memory 내 dirty page를 디스크에 내려쓰는 프로세스입니다.
- shared buffer의 dirty page를 디스크로 주기적으로 flush 수행
- 주기적인 checkpoint 발생 시 모든 dirty page를 디스크에 기록
이 중 첫번째 작업은 dirty page를 미리 조금씩 flush 해놔서 checkpoint 동작 때 I/O가 몰리지 않도록 하자
즉, 시스템 I/O load 의 부담을 줄이기 위한 동작이라고 볼 수 있습니다.
관련 parameter
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # max buffers written/round, 0 disables
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disables
- bgwriter_delay : 두 번의 연속적인 flush 동작 간 delay 설정
- bgwriter_lru_maxpages : bgwriter가 한번에 내려쓰는 데이터 단위로 dirty page가 100 보다 더 많으면 서버 프로세스에서 처리됨
WalWriter
Write Ahead Logging의 개념은 데이터 파일의 수정은 변경 사항이 로그에 먼저 기록 된 후에만 이루어져야한다는 것입니다.
이 메커니즘을 사용하면 디스크에 데이터를 자주 내려 쓰지 않고 disk I/O를 줄일 수 있습니다.
또한 WAL 로그를 사용하여 dbms 를 최근 시점까지도 복구할 수 있습니다.
관련 파라미터
#------------------------------------------------------------------------------
# WRITE-AHEAD LOG
#------------------------------------------------------------------------------
# - Settings -
wal_level = logical # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
# (turning this off can cause
# unrecoverable data corruption)
#synchronous_commit = on # synchronization level;
# off, local, remote_write, remote_apply, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
#wal_log_hints = off # also do full page writes of non-critical updates
# (change requires restart)
#wal_init_zero = on # zero-fill new WAL files
#wal_recycle = on # recycle WAL files
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)
#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after = 1MB # measured in pages, 0 disables
#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000
- wal_level : WAL logfile에 기록되는 정보의 수준, 기본값인 replica 부터 streaming replication 과 hot standby를 사용할 수 있음
- fsync : 변경사항을 WAL logfile 로 내려쓰겠다는 설정, off 설정 시 성능 상 이점이 있으나 crash 발생하면 데이터 손실남
- synchronous_commit : ON 설정 시 변경사항이 WAL logfile 에 기록되어야 트랜잭션 완료
- wal_sync_method : 변경사항을 WAL logfile로 내려쓰는 방법, fsync, fdatasync 등이 있음
- full_page_writes : 전체 data page를 WAL log에 쓰도록 설정
- wal_buffers : WAL log를 저장하는 데 사용되는 메모리 공간, wal_writer_delay, commit_delay 설정에 영향받을 수 있음
- wal_writer_delay : walwriter 프로세스의 동작 간격 설정으로, 시간이 너무 길면 WAL buffer가 부족할 수 있으며 시간이 너무 짧으면 WAL을 계속 쓰게되어 디스크 I/O 부담이 증가할 수 있음
- commit_delay : commit 이후 WAL flush 되기 전 WAL buffer에서 대기하는 시간, group commit 과 같은 효과
- commit_siblings : commit delay 설정을 수행하기 전, 필요한 최소 동시 트랜잭션 수, 트랜잭션 수가 commit_siblings 보다 적은 경우 바로 WAL flush 됨.
PgArch 프로세스
WAL logfile은 재활용 되기 때문에 과거의 WAL logifle은 새로운 log로 덮어 씌여집니다.
중간에 WAL logfile이 유실되는 경우 원하는 시점으로 시점복구가 어려울 수 있기 때문에 PostgreSQL에서는 WAL logfile을 백업해놓을 수 있는데 이때 역할을 수행하는 프로세스가 PgArch 프로세스입니다.
관련 파라미터
# - Archiving -
#archive_mode = off # enables archiving; off, on, or always
# (change requires restart)
#archive_command = '' # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disables
- archive_mode : WAL logfile을 백업하는 archive_mode 설정 여부
- archive_command : WAL 로그를 백업하기 위해 실행 될 명령어. %p : 아카이브해야하는 WAL logfile의 경로, %f : 파일 이름
AutoVacuum 프로세스
PostgreSQL 은 UPDATE, DELETE 작업을 수행 한 후 이전 버전의 데이터를 즉시 삭제하지 않고 레코드에 저장해 놓습니다.
대신, 데이터는 PostgreSQL의 MVCC 메커니즘에 의해 삭제 된 것으로 표시하고 이전 버전의 데이터에 다른 트랜잭션이 액세스하는 경우 임시로 유지합니다.
트랜잭션이 commit 된 후에는 이전 버전의 데이터가 더 이상 필요하지 않으므로 (데드 튜플) PostgreSQL은 공간 및 xid 확보를 위해 데이터를 정리해야합니다.
이 작업은 AutoVacuum 프로세스에서 수행됩니다.
관련 파라미터
#------------------------------------------------------------------------------
# AUTOVACUUM
#------------------------------------------------------------------------------
#autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
# before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
- autovacuum : autovacuum 프로세스를 사용할지 여부
- autovacuum_max_workers : autovacuum 을 병렬로 수행할 최대 서브 프로세스 수 설정
- autovacuum_naptime : 두 autovacuum 프로세스 사이의 간격 시간을 설정
- autovacuum_vacuum_threshold / autovacuum_analyze_threshold : 테이블에서 업데이트 된 튜플 수의 임계 값 설정 , 튜플 업데이트 수가 이 값을 초과하면 vacuum / analyze 수행 필요
- autovacuum_vacuum_scale_factor / autovacuum_analyze_scale_factor : 설정한 배율만큼 테이블 내 데이터 변경 시, autovacuum이 수행될 테이블로 추가됨
- autovacuum_freeze_max_age : 테이블의 최대 유효 xid, 이 값 이상으로 xid가 커지지 않도록 vacuum 수행함
통계 수집기
PostgreSQL optimizer의 쿼리 최적화를 위해 테이블 메타정보, 삭제 / 업데이트 수, 데이터 블록 수, 인덱스 변경 등과 같은 데이터베이스 작업 중 통계 정보를 수집하는 프로세스입니다.
관련 파라미터
#------------------------------------------------------------------------------
# STATISTICS
#------------------------------------------------------------------------------
# - Query and Index Statistics Collector -
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#stats_temp_directory = 'pg_stat_tmp'
- track_activities : 세션에서 현재 실행중인 명령에 대한 통계 정보 수집 기능을 사용할지 여부
- track_counts : 데이터베이스 내 모든 작업에 대한 통계 정보 수집 기능을 사용할지 여부
- track_io_timing : 쿼리 수행 시 I/O 소요시간을 수집함
- track_functions : 함수 호출 수 및 수행 시간 수집
- track_activity_query_size : 각 세션에서 현재 실행 중인 커맨드의 텍스트를 저장하는데 사용할 메모리
- stats_temp_directory : OS 상 통계 정보의 임시 저장 경로
checkpointer
checkpoint는 DBMS가 설정하는 트랜잭션 포인트입니다. checkpoint가 실행되면 checkpoint 이전의 모든 변경사항이 디스크로 flush 됩니다.
DBMS가 crash 된 후 복구할 때도 checkpoint 이후 시점의 WAL log를 반영하여 복구하게됩니다.
관련 파라미터
# - Checkpoints -
#checkpoint_timeout = 5min # range 30s-1d
max_wal_size = 1GB
min_wal_size = 80MB
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
- checkpoint_timeout : 설정한 시간 마다 checkpoint 수행
- max_wal_size : WAL logfile 의 사이즈가 1GB 이상 되면 checkpoint 수행
- min_wal_size : WAL logfile 사이즈가 해당 값 미만이면 checkpoint 발생시 WAL logfile을 지우지 않고 재활용함
- checkpoint_completion_target : 다음 checkpoint 가 발생하기 전 checkpoint_timeout * checkpoint_completion_target 시간 안에 checkpoint 완료되도록 목표 지정하는 설정