gin index
이전 글에서 살펴보았듯이 vacuum은 쿼리의 실행계획과 성능에도 큰 영향을 끼칩니다.
Index Only Scan이지만 dead tuple의 여부에따라 테이블에 접근하는 것을 보았다면
이번 글에서는 fulltext index인 gin index에서 vacuum이 어떤 영향을 줄 수 있는지를 살펴보겠습니다.
gin index는 PostgreSQL에서 text, json, array 검색을 지원하는 인덱스로
gin_trgm_ops, jsonb_ops,jsonb_path_ops 등 여러 인덱스 연산자를 지원합니다.
MySQL도 fulltext index를 지원하고 ngram을 기반으로 동작하는 것은 동일하지만 MySQL보다 더 유연하여
일반 컬럼과 fulltext 컬럼을 결합인덱스로 생성한다던가, 락 없이 fulltext index를 생성할 수 있는 등의 장점이 있습니다.
다만, 그 아키텍처가 복잡하고 또 vacuum과도 엮여 있어서 운영하기 어려울 수 있는데요.
이번 글에서는 gin index의 아키텍처를 간단히 살펴보고, vacuum과 어떤 관계가 있는지를 살펴보겠습니다.
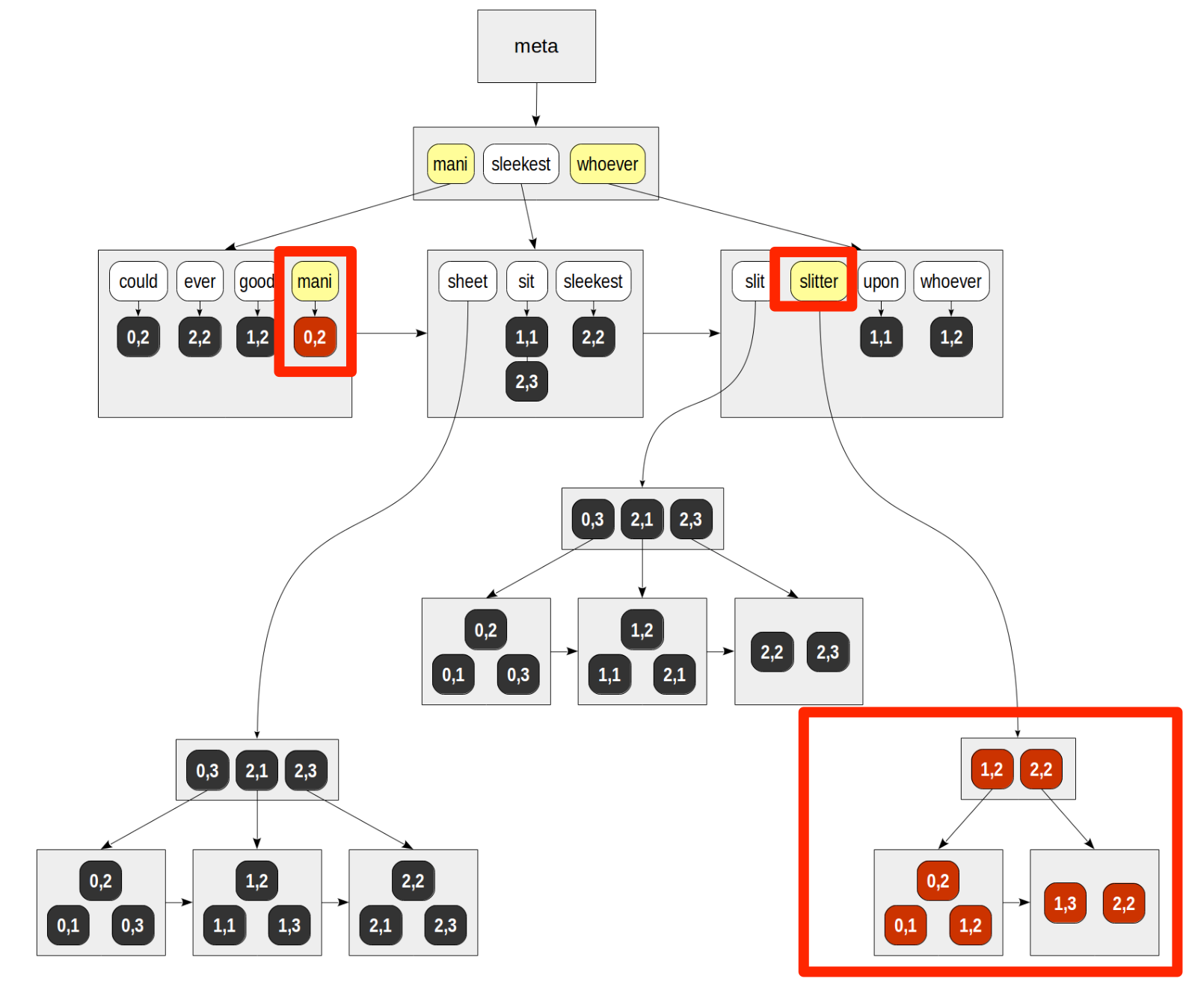
gin index는 위와같이 단어 수준에서 btree로 저장되는데 이때 해당 단어가 포함되는 TID를 함께 저장합니다.
그리고 포함되는 TID가 너무 많다면 그 아랫단에 posting tree 라는 구조로 저장됩니다.
여기서 TID는 해당 레코드가 속한 page, 즉 block에서의 위치를 의미합니다.
testdb=> create table ts(doc text, doc_tsv tsvector);
testdb=> insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
testdb=> update ts set doc_tsv = to_tsvector(doc);
testdb=> create index on ts using gin(doc_tsv);
testdb=> select ctid, doc, doc_tsv from ts;
ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------
(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4
(0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7
(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8
(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1
(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5
(2,1) | I slit sheets. | 'sheet':3 'slit':2
(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
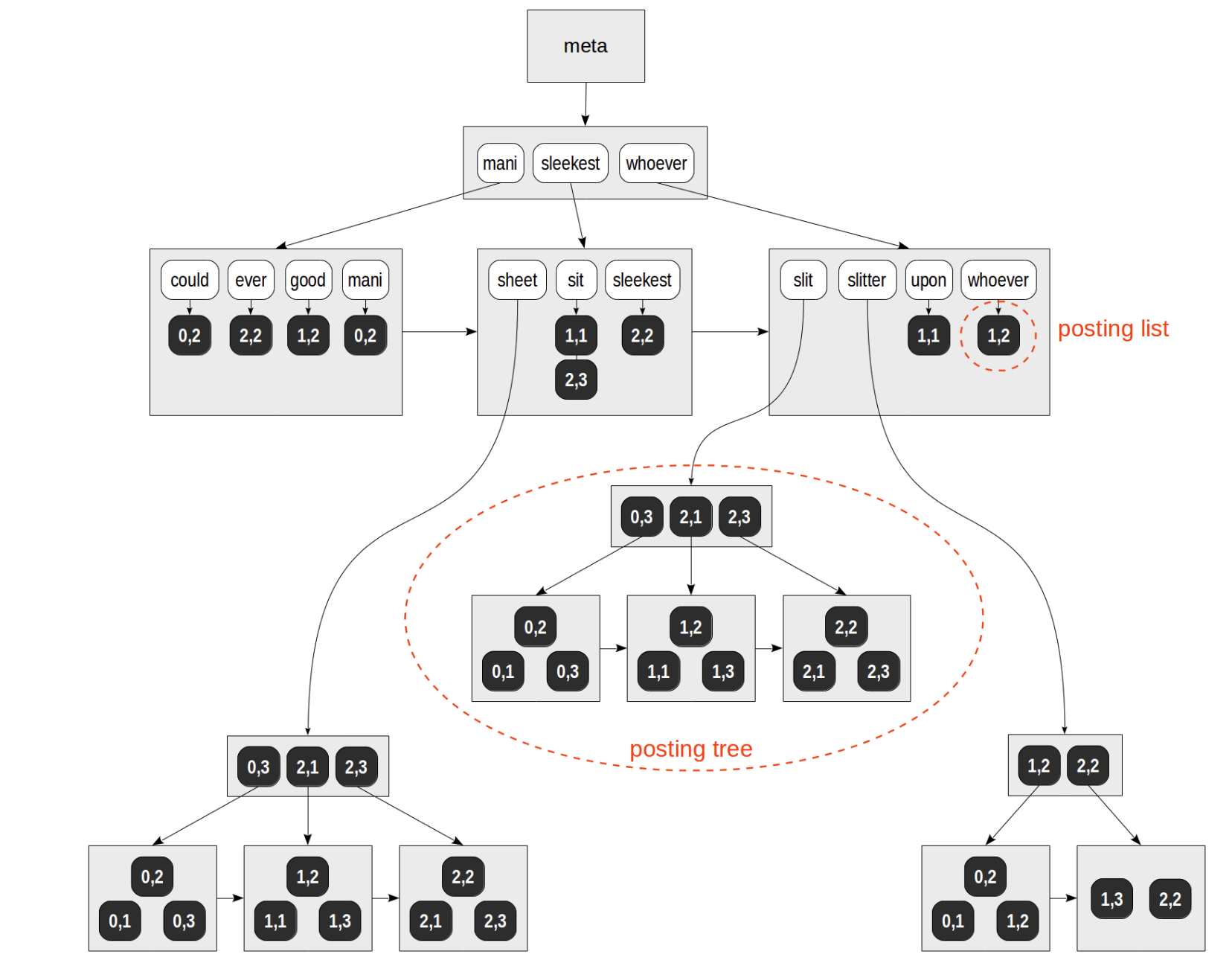
위 그림과 실제 데이터의 ctid는 좀 다르지만, 의미하는 바는 같습니다.
gin index의 entry page에는 단어와, 그 단어가 위치한 tid가 함께 저장되는 구조입니다.
예를들어 아래 그림에서 mani 라는 단어는 (0,2) tid 하나에만 저장되어있고 slitter 이라는 단어는 여러 tid에 속해있어서 해당 tid를 저장한 posting tree로 따로 관리되고 있습니다.
gin index의 fastupdate와 pending list
gin index의 가장 큰 단점은 일반 b-tree보다 DML cost 비용이 더 비싸다는 점입니다.
위에서 봤듯이 하나의 row에 있는 각각의 단어들이 indexig 되기 때문에, 하나의 row에 대한 DML이 여러개의 index page를 업데이트해야 하기 때문입니다.
비용은 어쩔수없다쳐도 여러개의 index page를 업데이트 하다보면 DML 성능도 문제가 될 수 있는데
gin index에서는 이것을 pending list, fast update 기능을 통해 관리하고 있습니다.
MySQL의 change buffer와 비슷한 개념이라고 볼 수 있는데
fastupdate 기능을 on 하면, 업데이트할 gin index 데이터들을 pending list에 정렬되지 않은 채로 쌓아놓습니다.
이 방식은 건건마다 gin index가 업데이트 되는 것을 피하는 효과는 있지만,
쿼리 시 pending list 에 있는 데이터도 읽어야하기 때문에 좀 느릴 수 있고
쌓아뒀던 정렬되지 않은 데이터를 gin index에 반영할 때 업데이트 부하가 심할 수 있다는 단점이 있습니다
마치 checkpoint할 때 한번에 쓸 데이터가 많으면 부하가 되는 것 처럼요
그리고 아래의 경우에 쌓아놨던 데이터들을 gin index에 반영하게 됩니다.
- gin_pending_list_limit (deafult 4mb) 초과
- gin_clean_pending_list 함수 호출할때
- gin index가 있는 테이블에 vacuum이 수행될때
그리고 이를 이용하면 gin index의 fastupdate로 인한 부하를 조금이라도 더 줄여볼 수 있는데요
gin_pending_list_limit 사이즈를 줄이거나
ex) 4mb->1mb
ALTER INDEX "tb_test_idx_gin" SET ( gin_pending_list_limit = 1048576 ) ;
autovacuum의 수행빈도를 더 자주 돌려서 pending_list를 금방금방 비워주는 것입니다.
pending_list에 데이터가 많이 쌓여서 한번에 반영하는 것이 부하가 된다면, 조금씩 더 많이 반영하는 식으로 부하를 좀 덜어보자 하는 방식입니다.
그 외에도 아래 파라미터를 튜닝하는 것도 도움이 됩니다.
- work_mem during regular INSERT/UPDATE
- maintenance_work_mem during gin_clean_pending_list() call
- autovacuum_work_mem during autovacuum
그럼 마지막으로 pending_list에 데이터가 쌓이면 정말 성능이 느려질지,
그리고 vacuum을 돌려주면 성능이 개선될지 테스트를 통해 확인해보겠습니다.
vacuum 테스트
- 테스트 데이터 준비
testdb=> CREATE EXTENSION pgstattuple;
CREATE EXTENSION
testdb=> CREATE TABLE tb_test (
test_text text
)
WITH (autovacuum_enabled = off);
CREATE TABLE
testdb=> CREATE INDEX tb_test_gin ON tb_test USING gin (test_text gin_trgm_ops);
CREATE INDEX
testdb=> INSERT INTO tb_test
SELECT
md5(random()::text)
from (
SELECT * FROM generate_series(1,100000) AS id
) AS x;
INSERT 0 100000
testdb=> vacuum tb_test
VACUUM
testdb=> SELECT * FROM pgstatginindex('tb_test_gin');
version | pending_pages | pending_tuples
---------+---------------+----------------
2 | 0 | 0
(1 row)
=> gin index 생성, 데이터 적재 후 vacuum을 수행하여 pending_list를 모두 비워줌
- pending_list가 비어있을 때 쿼리 실행계획
testdb=> explain (analyze, buffers)
select * from tb_test where test_text like '%aaaaa%';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tb_test (cost=17.24..419.98 rows=160 width=32) (actual time=0.724..0.996 rows=6 loops=1)
Recheck Cond: (test_text ~~ '%aaaaa%'::text)
Rows Removed by Index Recheck: 690
Heap Blocks: exact=477
Buffers: shared hit=481
-> Bitmap Index Scan on tb_test_gin (cost=0.00..17.20 rows=160 width=0) (actual time=0.121..0.121 rows=696 loops=1)
Index Cond: (test_text ~~ '%aaaaa%'::text)
Buffers: shared hit=4
Planning:
Buffers: shared hit=5
Planning Time: 0.100 ms
Execution Time: 1.025 ms
(12 rows)
=> pending list가 비어있을 땐 gin index를 이용하여 bitmap scan을 하고 총 481개의 page를 읽음
- pending_list를 채운 뒤 쿼리 실행계획
testdb=> truncate tb_test;
TRUNCATE TABLE
testdb=> INSERT INTO tb_test
SELECT
md5(random()::text)
from (
SELECT * FROM generate_series(1,100000) AS id
) AS x;
INSERT 0 100000
testdb=> SELECT * FROM pgstatginindex('tb_test_gin');
version | pending_pages | pending_tuples
---------+---------------+----------------
2 | 108 | 1296
(1 row)
testdb=> explain (analyze, buffers)
select * from tb_test where test_text like '%aaaaa%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tb_test (cost=449.41..889.49 rows=181 width=32) (actual time=1.232..1.539 rows=6 loops=1)
Recheck Cond: (test_text ~~ '%aaaaa%'::text)
Rows Removed by Index Recheck: 690
Heap Blocks: exact=477
Buffers: shared hit=589
-> Bitmap Index Scan on tb_test_gin (cost=0.00..449.36 rows=181 width=0) (actual time=0.620..0.620 rows=696 loops=1)
Index Cond: (test_text ~~ '%aaaaa%'::text)
Buffers: shared hit=112
Planning:
Buffers: shared hit=3
Planning Time: 0.102 ms
Execution Time: 1.565 ms
(12 rows)
=> truncate 후 vacuum을 돌려주지 않아 pending_list에 108개의 page가 있는 상태
동일한 쿼리를 수행했을 때 기존보다 pending pages 108개 만큼 더 읽어서 589개의 페이지를 읽은 것을 확인할 수 있음 481 (기존) + 108 (pending list) = 589
pending list의 데이터를 더 읽으면서 execution time도 늘어난 것을 확인할 수 있다
결론
- PostgreSQL의 gin index는 MySQL보다 더 강력하고 유연한 fulltext search를 지원하지만
- 아키텍처상 DML 부하가 심할 수 있으며 이를 잘 관리하기 위해서는 autovacuum이 잘 돌아야한다!