PostgreSQL의 MVCC 는 ORACLE이나 MySQL의 동작 방식과 다릅니다.
과거 데이터를 별도의 UNDO 영역에 저장하는 게 아니라 과거의 tuple을 invalid 처리 후
update 후의 새로운 tuple 을 추가하는 방식으로 동작하는데요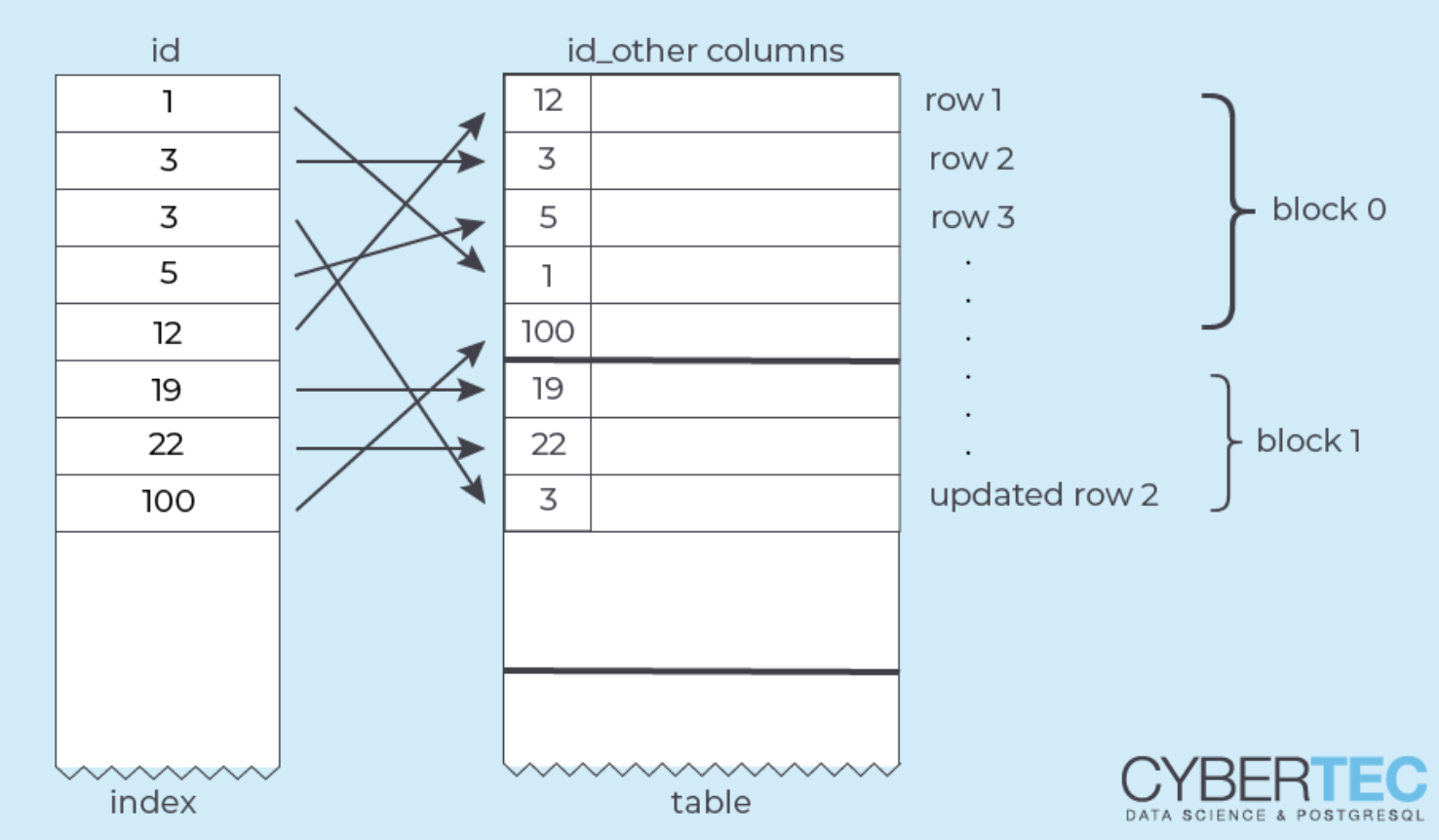
장점으로는
- UNDO 영역을 따로 관리할 필요가 없다
- ROLLBACK 처리기 매우 빠르다
단점으로는
- invalid 된 오래된 dead tuple들을 정리할 vacuum 작업이 필요하다
- 과도한 업데이트로 인한 dead tuple 로 테이블이 비대해 질 수 있다
- update 로 인한 인덱스 수정이 필요하다
같은 장단점이 있습니다.
그리고 이를 어느정도 해소하기 위한 방법이 HOT (Heap Only Tuple) 업데이트 방식인데요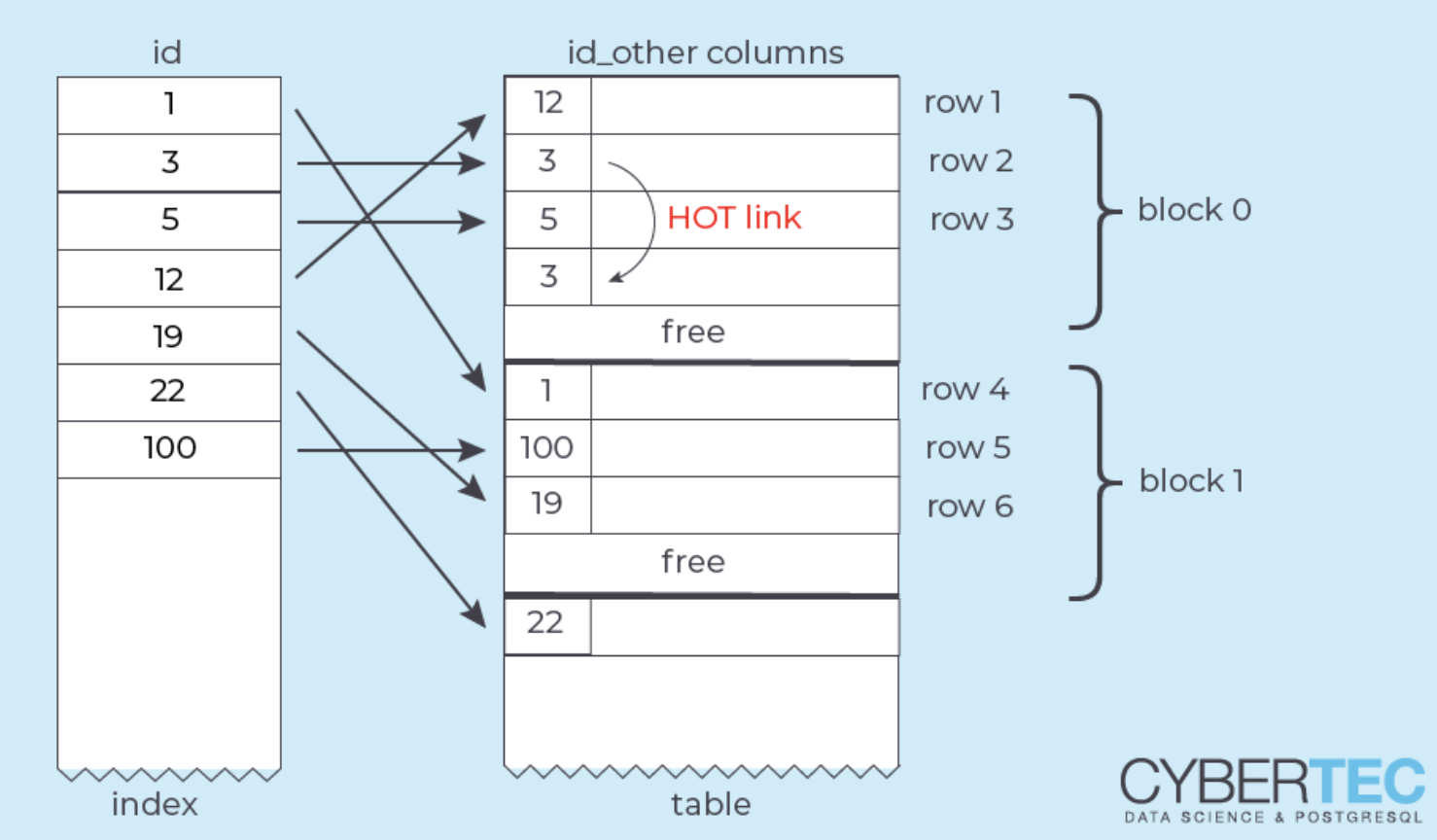
그림처럼 테이블 block 외부에서는 어디서도 참조되지 않는 HOT tuple 을 생성합니다.
그리고 이 HOT tuple 의 위치는 old version의 row가 갖고 있는데
마치 pointer 처럼 old version의 row, HOT chain을 따라
새로 업데이트된 HOT tuple 에 도착할 수 있습니다.
이 방법에는 다음과 같은 장점이 있습니다.
- 인덱스를 수정할 필요가 없다 => tuple 의 외부 주소는 변한 게 없고 index 는 tuple의 HOT chain 을 따라가면되니까
- dead tuple에 대한 vacuum 부담이 적어진다.
이 HOT tuple을 이용한 update를 이용하려면 두가지 조건을 충족해야하는데
- block 에 공간이 충분해야한다 => old version의 tuple과 HOT tuple 이 같은 block 에 있어야함, 아래 그림의 (a)
- index key 값에 변경이 없어야 한다 => index key 값이 update 되어 변경이 생기면 새로운 인덱스 tuple이 생성됨,아래 그림의 (b)
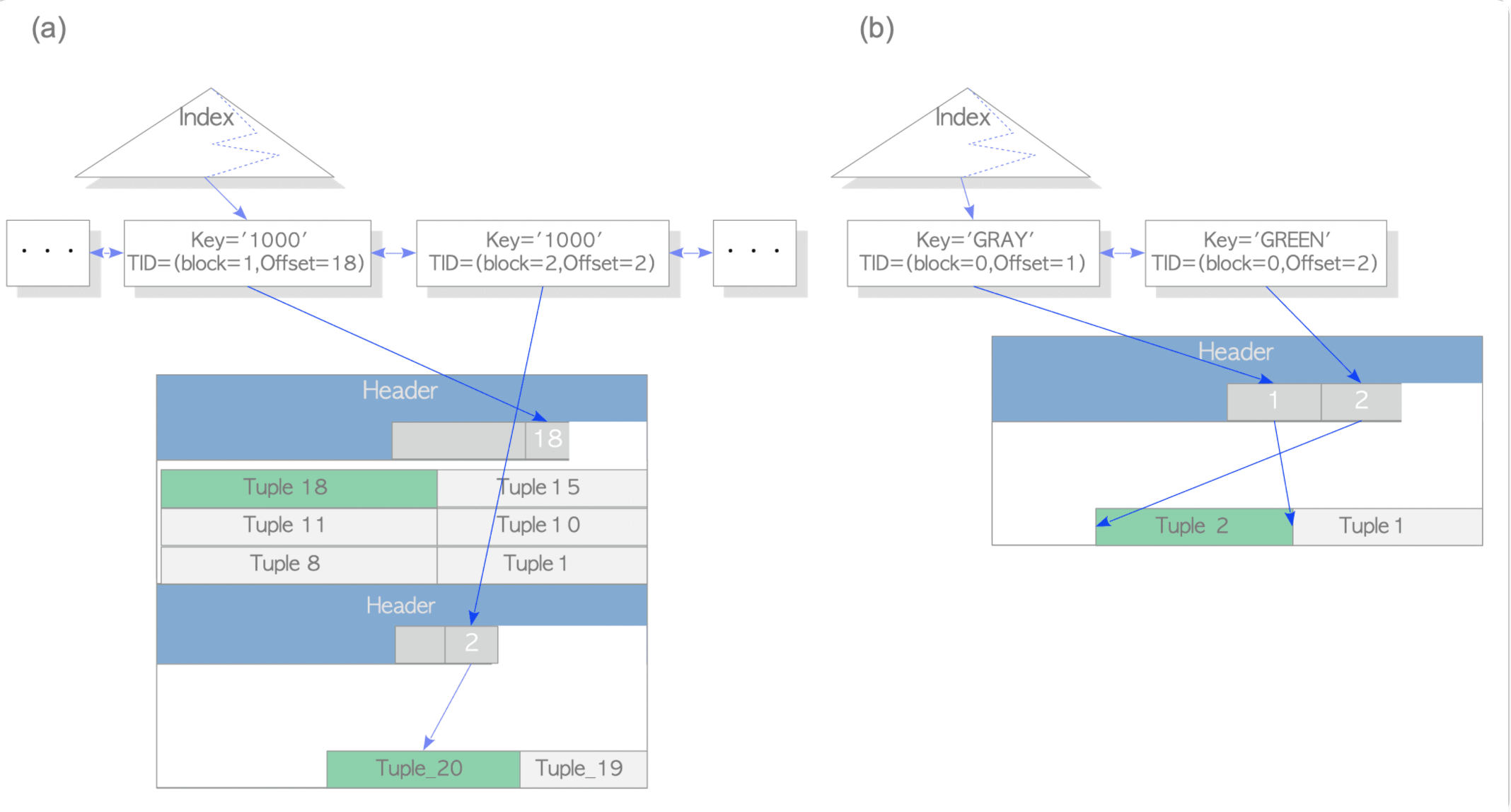
테스트
HOT tuple 미사용 시
- 데이터 생성
CREATE TABLE mytable (
id integer PRIMARY KEY,
val integer NOT NULL
) WITH (autovacuum_enabled = off);
INSERT INTO mytable
SELECT *, 0
FROM generate_series(1, 235) AS n;
SELECT ctid, id, val FROM mytable;
ctid | id | val
---------+-----+-----
(0,1) | 1 | 0
(0,2) | 2 | 0
(0,3) | 3 | 0
(0,4) | 4 | 0
(0,5) | 5 | 0
...
(0,224) | 224 | 0
(0,225) | 225 | 0
(0,226) | 226 | 0
(1,1) | 227 | 0
(1,2) | 228 | 0
(1,3) | 229 | 0
(1,4) | 230 | 0
(1,5) | 231 | 0
(1,6) | 232 | 0
(1,7) | 233 | 0
(1,8) | 234 | 0
(1,9) | 235 | 0
(235 rows)
=> id 1~226 까지 block 0, 그 이후의 데이터는 block 1 에 저장됨 확인
ctid 는 current tuple ID 로 oracle 의 rowid 와 비슷한 개념
- update 수행 후 CTID
UPDATE mytable
SET val = -1
WHERE id = 42;
SELECT ctid, id, val
FROM mytable
WHERE id = 42;
ctid | id | val
--------+----+-----
(1,10) | 42 | -1
(1 row)
=> update 된 id = 42 가 신규 block 으로 ctid (1,10) 에 생성됨,
old verseion 의 tuple 과 block이 달라졌기 때문에 새로운 ctid를 가리키는 index tuple이 새로 생성되어야 함
HOT tuple 사용 시
TRUNCATE mytable;
ALTER TABLE mytable SET (fillfactor = 70);
INSERT INTO mytable
SELECT *, 0 FROM generate_series(1, 235);
SELECT ctid, id, val
FROM mytable;
ctid | id | val
---------+-----+-----
(0,1) | 1 | 0
(0,2) | 2 | 0
(0,3) | 3 | 0
(0,4) | 4 | 0
(0,5) | 5 | 0
...
(0,156) | 156 | 0
(0,157) | 157 | 0
(0,158) | 158 | 0
(1,1) | 159 | 0
(1,2) | 160 | 0
(1,3) | 161 | 0
...
(1,75) | 233 | 0
(1,76) | 234 | 0
(1,77) | 235 | 0
(235 rows)
- update 후 CTID
UPDATE mytable
SET val = -1
WHERE id = 42;
SELECT ctid, id, val
FROM mytable
WHERE id = 42;
ctid | id | val
---------+----+-----
(0,159) | 42 | -1
(1 row)
=> fillfactor 는 ORACLE의 PCTFREE의 개념으로 block을 어느정도 사용할지 정하는 설정,
위에서는 테이블의 fillfactor를 70%로 설정하여 block의 70%만 사용하고 30%는 update를 위해 남겨두게 된다
그래서 update 수행 후 새로운 tuple이 새로운 block에 생성되는 게 아니라 old version의 tuple 과 같은 block 에 생성되어 인덱스 변경이 필요없음
old version의 tuple 이 update 된 새로운 tuple의 위치를 알려주는 HOT chain 방식을 이용하게된다
정리
postgresql 의 MVCC 는 UNDO 없이 old version, new version 모두 갖고 있는 방식으로 update 할 때 비효율이 있는데
이를 fillfactor 를 이용한 HOT 방식으로 어느정도 해소 할 수 있습니다.
참고로 fillfactor는 전역변수가 아니라 테이블 개별 설정이기 때문에
update 가 잦은 테이블은 fillfactor를 조절하여 HOT update 의 효과를 볼 수 있습니다.