시작하며
세상엔 저마다의 특징과 장점을 뽐내는 다양한 DBMS들이 있습니다.
이들 각각의 특장점이 무엇인지 파악하고 자신의 서비스에서 어떤 DBMS가 최고의 퍼포먼스를 낼 수 있는지 파악하는 것이 중요하기 때문에
다양한 DBMS 에 대한 이해가 점점 중요해지고 있습니다.
ORACLE은 강력한 엔터프라이즈 개발 기능과 안정성을, MySQL은 대표적인 오픈소스 DB로 뛰어난 OLTP 성능을 보여주고, CUBRID는 뛰어난 부하 분산 기능을 자랑하는 DBMS입니다.
그리고 이 글에서 소개해드릴 PostgreSQL은 GIS 지리 정보 처리와 엔터프라이즈급 DBMS의 기능을 제공하는 오픈소스 DBMS입니다.
PostgreSQL은 이미 북미와 일본쪽에서는 굉장히 인기가 많은 DB로 자리잡은데 비해
우리나라에서는 GIS 용도로 굳어버린 이미지 때문인지 활용도가 높은 DB는 아닌데요.
GIS 외에도 기능과 성능면에서 굉장히 뛰어난 오픈소스 DB이기 때문에 알아둘 가치가 충분한 DB입니다.
이번 글에서는 PostgreSQL의 Architecture에 대해 다루면서 이게 어떤 DBMS인지 알아보겠습니다.
PostgreSQL

PostgreSQL은 객체관계형 데이터베이스 (ORDBMS) 로 엔터프라이즈급 DBMS의 기능과 뛰어난 GIS 기능으로 유명한 오픈소스DB입니다.
객체지향 모델을 지원하기 때문에 개발자 스스로 어플리케이션에 필요한 data type과 method를 정의할 수 있습니다.
PostgreSQL이 GIS 분야에서 뛰어난 이유도 ORDBMS의 특성을 살려 Native 수준으로 Spatial SQL 요소들을 구현한 PostGIS 라는 Add-on 이 있기 때문입니다.
1986년부터 30년이상 활발하게 개발되고 있는 PostgreSQL은 현재 13.1 beta 버전이 출시되었으며
MVCC, 트랜잭션 ACID 등 기본적인 RDBMS 기능 뿐만 아니라 extension이라 불리는 확장 모듈 API를 통해 다양한 기능을 제공하고 있습니다.
- PostgreSQL 소개 : https://www.postgresql.org/about/
- PostgreSQL extension list : https://postgresql.kr/docs/current/contrib.html
PostgreSQL Architecture
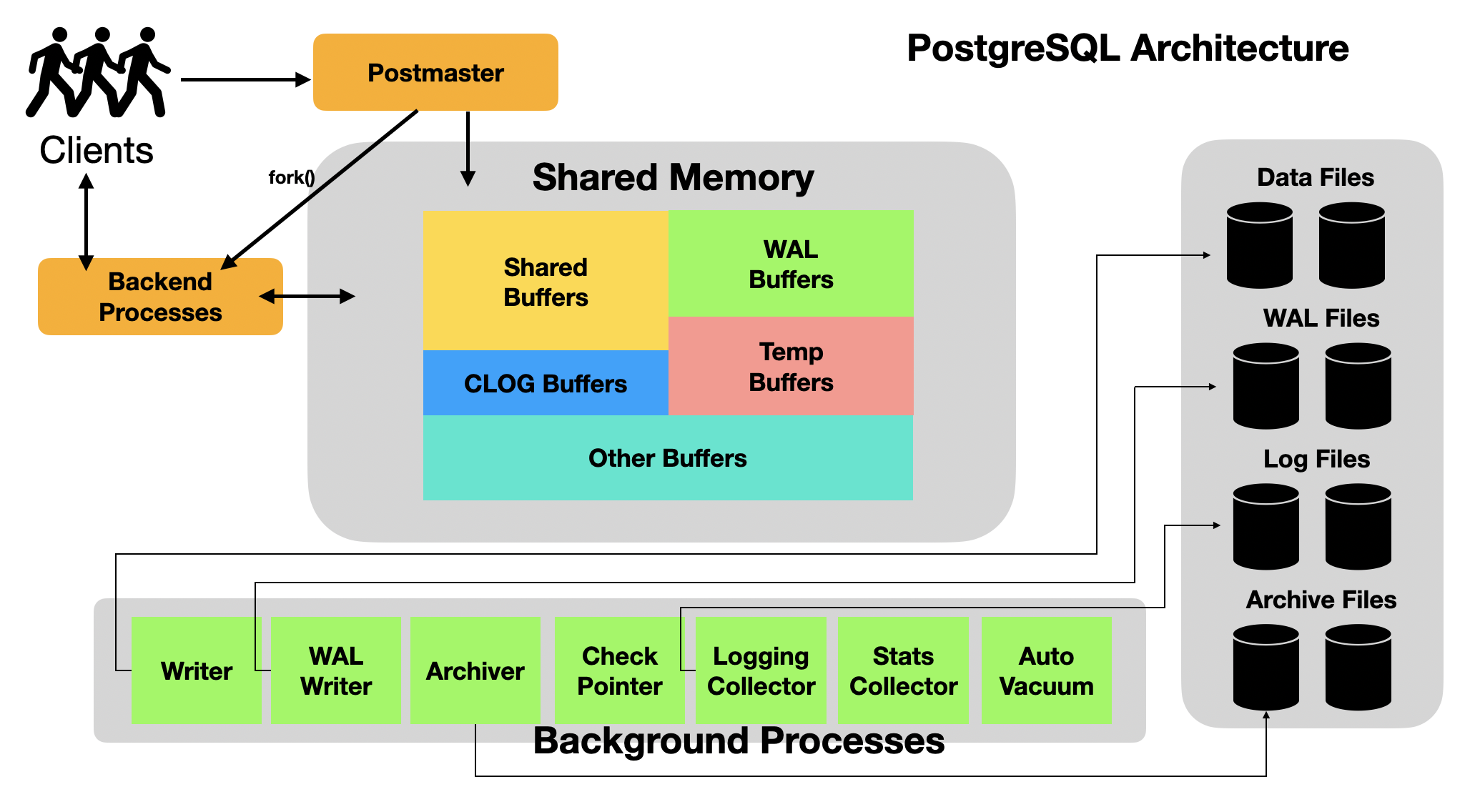
PostgreSQL의 아키텍처입니다
ORACLE 아키텍처에 대해 공부해보신 분이라면 바로 느끼시겠지만 전체적인 아키텍처가 ORACLE과 굉장히 유사합니다.
Shared Memory라는 공유메모리가 있고 PostgreSQL 운영에 필요한 Background process들과 Data file들로 구성됩니다.
Shared Memory
Shared Memory에서 가장 중요한 요소는 Shared Buffer와 WAL buffer입니다.
- Shared Buffer : Disk IO를 최소화하기 위해 데이터를 캐싱하는 공간
- WAL buffer : Write Ahead Logging 을 위한 공간으로 데이터베이스의 변경 사항을 WAL file로 내리기 전까지 보관
PostgreSQL은 데이터를 변경하기 전에 항상 변경 로그부터 기록하는데요
Shared Buffer의 데이터를 변경하기 전에 먼저 WAL buffer에 로그를 기록하고, writer process 가 dirty block 을 disk로 내려쓰기 전에
WAL writer process가 WAL logfile로 내려쓰는 작업을 먼저 하는데 변경 로그부터 작업한다하여 이를 Write Ahead Logging 이라고 부릅니다.
Shared Memory에서 가장 중요한 공간인만큼 관련 parameter의 적절한 설정도 중요한데요
권장값과 관련 설정은 이전 글을 참고하시기 바랍니다.
https://kimdubi.github.io/postgresql/psql_conf/
PostgreSQL Process
- Postmaster Process
Shared Memory 위에 보이는 Postmaster process 는
PostgreSQL을 기동할 때 가장 먼저 시작되는 Daemon 프로세스로
DB 기동 시에 recovery 작업, Shared Memory 초기화 작업
그리고 다른 background process 구동 작업을 수행하는 역할을 합니다.
또한 클라이언트 프로세스(JDBC,ODBC등..)의 접속 요청이 있을 때
backend process 를 fork하여 client process와 연결시켜주는 역할을 합니다.
- Background Process
운영에 필요한 PostgreSQL background process는 아래와 같습니다.
| Process 명 | 역할 |
|---|---|
| writer | 주기적으로 Shared Buffers 내 dirty 버퍼를 data file로 내려씁니다 |
| WAL writer | WAL buffer 내용을 WAL file에 기록합니다 |
| Checkpointer | 체크포인트 발생 시 dirty 버퍼를 data file에 기록합니다 |
| Archiver | Archive log 모드 일 때 WAL 파일을 지정된 archive 디렉토리에 복사합니다 |
| Logging collector | error 메시지를 log file에 기록합니다 |
| Stats collector | DBMS의 세션 정보, 테이블 통계 같은 정보를 수집합니다 |
| Autovaccum | vacuum이 필요한 시점에 autovacuum worker를 fork하여 vacuum 작업을 수행합니다 |
- Backend Process
Backend process 는 client process 의 쿼리 요청을 수행하고 그 결과를 전송하는 프로세스입니다.
이 때 쿼리 수행에 필요한 메모리가 필요한데 이를 backend process의 local memory라고 부릅니다.
Shared Memory와 마찬가지로 적절한 parameter 튜닝을 통해 성능을 최적화하는 것이 중요합니다.
여기까지 PostgreSQL의 Architecture에 대해 살펴보았는데 어떠신가요?
개인적으로는 ORACLE의 아키텍처와 유사해서 친숙하기도 했고 혹시 차이점은 없읕까 더 궁금하기도 했습니다.
다음으로는 제가 생각하는 ORACLE과 PostgreSQL의 가장 큰 차이점을 살펴보며 PostgreSQL Architecture에 대해 조금 더 알아보도록 하겠습니다.
ORACLE과 PostgreSQL Architecture 차이점
MVCC 모델 구현
대다수의 RDBMS는 동시성을 위해 MVCC(Multi-Version Concurrency Control) 기능을 제공합니다.
MVCC란, 쿼리 수행 시점의 데이터를 제공하는 기법으로 기본 원리는 쿼리가 시작된 시점의 트랜잭션ID와 같거나 작은 데이터 버전을 읽는 것 입니다.
ORACLE과 MySQL 같은 경우에는 UNDO segment를 사용하며 쿼리가 시작된 이후에
다른 트랜잭션에 의해 변경된 블록을 만나면 원본 블록으로부터 복사본 블록 (CR copy)를 만들고
그 복사본 블록에 UNDO segment를 적용하여 쿼리가 시작된 시점으로 되돌려서 읽는 방식을 사용합니다.
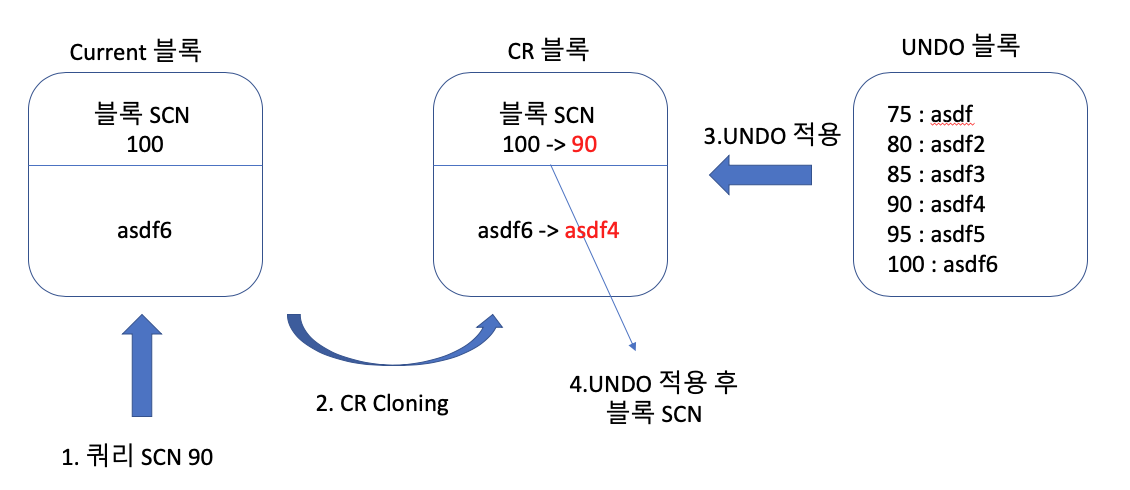
[ORACLE 의 UNDO 동작방식]
반면에 PostgreSQL은 데이터 페이지 내에 변경되기 이전 레코드를 저장 하고
레코드 별로 생성된 시점과 변경된 시점을 기록 및 비교하는 방식 으로 MVCC를 제공합니다.
이 방식은 ORACLE의 UNDO segment 같은 복잡성 없이 MVCC를 매우 단순하게 구현할 수 있도록 하는 장점이 있습니다.
다만 이전 데이터와 현재의 데이터를 동일한 테이블 내에 저장하기 때문에 테이블 공간이 비효율적으로 사용될 수 있습니다.
또한 사용할 수 있는 트랜잭션 ID가 고갈되고 덮어써져 (wrap around) 오래된 데이터가 손실될 가능성이 있습니다.
PostgreSQL에서는 이전의 데이터와 현재의 데이터를 구분하고 시점에 맞는 데이터를 사용하기 위해서는 레코드별로 트랜잭션ID (이하 XID)가 필요한데
PostgreSQL에서는 XID를 위해 4바이트를 사용하고 있어 최대 43억건의 XID를 표현할수 있습니다.
만약 43억건 이후 XID 를 1부터 다시 시작하게 되면 어떻게 될까요?

아래의 새로 시작된 XID 1은 43억보다 이후의 트랜잭션이지만
XID가 작아서 더 오래된 트랜잭션으로 인식되어 순서가 꼬여버리는 치명적인 문제가 발생할 수 있습니다.
- 불필요한 데이터로 인한 테이블 공간 사용의 비효율성
- XID를 4bytes 로 관리함에 따른 XID 고갈
이 두가지 이슈를 해결하기 위한 PostgreSQL의 내부 동작이 vacuum 입니다.
위에서 언급한 autovacuum 백그라운드 프로세스는 테이블에 일정량 이상의 변경이 발생한 경우
자동으로 vacuum을 수행하면서 더 이상 사용하지 않는 dead-rows 를 회수하고 오래된 XID 를 정리하는 역할을 수행합니다.
즉 vacuum은 PostgreSQL 특유의 MVCC 모델에서 비롯될 수 있는 문제점을 해결하기 위해 나온 개념인 것입니다.
Shared Pool의 부재
PostgreSQL은 ORACLE의 Shared Pool같은 기능을 제공하지 않습니다.
Shared pool은 수행한 쿼리의 Parse tree나 Execution plan, 데이터베이스 내 오브젝트 정보를 갖고 있는 공간으로
ORACLE에서는 굉장히 중요한 구성요소이기 때문에 개인적으로 놀라운 부분이기도 했는데요.
PostgreSQL은 공유 메모리 레벨이 아닌 프로세스 레벨에서 SQL 정보를 공유합니다.
이를 통해 Shared pool 리소스나 Shared pool latch 경합 같은 관리 포인트를 줄일 수 있지만 신규 커넥션 마다 수행하는 SQL에 대해 최초 1회는 hard-parsing 이 필요하게 됩니다.
그렇기 때문에 Connection pool 기능을 사용하면 도움이 되겠죠?
Pgpool-II , PGbouncer 같이 connection pooling, load balancing 등을 지원하는 PostgreSQL 오픈소스 툴을 도입해서 사용하면 더 좋은 성능을 이끌어 낼 수 있습니다.