Master - Slave 구성으로 운영중인 서비스가 있습니다.
maxmemory, key ttl, hash key 하나에 너무 많은 value 넣지 않기 등
운영 표준을 잘 지켜가며 안정적으로 운영중인 서비스인데 어느 순간부터인지 이런 로그들이 떨어지면서 Master - Slave 연결이 자꾸 끊어지는 현상이 발생했습니다.
replconf scheduled to be closed ASAP for overcoming of output buffer limits.
Connection with replica 10.111.111.111:6379 lost.
psync scheduled to be closed ASAP for overcoming of output buffer limits.
output buffer limits 라는 부분이 눈에 띄는데 redis에는 client-output-buffer-limit 라는 설정이 있습니다.
redis는 클라이언트의 요청을 처리하기 위해 클라이언트를 normal, slave, pubsub으로 나누어 buffer를 할당합니다.
따로 할당되는 repl-backlog-size 와는 달리 client buffer는 redis의 maxmemory에서 할당되는데 buffer를 무한정 크게 사용하거나 오랜시간 동안 사용하면
redis memory에 직접적으로 영향을 줄 수 있기 때문에 limit 을 두고 관리하고 이 limit 에 관한 설정이 바로 client-output-buffer-limit 입니다.
### redis.conf default
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
각각 [type] [hard limit] [soft limit] [time] 을 의미하며
- hard limit : 이 값 이상 사용하게 되면 해당 연결을 종료시킴 ex) 256mb 이상 사용하게 되면 바로 컽
- soft limit : 이 값 이상으로 time 만큼 세션이 지속되면 해당 연결을 종료시킴 ex) 64mb이상 60초 넘게쓰면 컽
이 설정을 default로 사용할 때 처음에는 데이터가 많지 않기 때문에 별 이슈가 없지만 master에 데이터가 많이 유입될 때 문제가 생깁니다.
master에는 제한 없이 데이터가 유입되지만(normal 0 0 0) 이를 slave (replica)로 복제를 위해 전달할 때 client-output-buffer-limit slave 256mb 64mb 60
이 설정에 영향을 받게되는데 데이터가 크면 이 제한에 걸려 연결이 끊어져 버릴 수 있습니다.
그래서 위에서 봤던 로그와 함께 Master - Slave 연결이 끊어져 버리는 것입니다.
replconf scheduled to be closed ASAP for overcoming of output buffer limits.
Connection with replica 10.111.111.111:6379 lost.
연결이 끊어지면 무엇이 문제일까요?
Slave는 다시 Master에게 동기화를 요구하게 되고 이를 위해 Master 는 RDB dump file을 떨구게 됩니다.
연결이 자꾸 빈번하게 끊어져 계속 rdb 가 발생하게 되면 Master는 자신이 해야할일을 하지 못하게되고 부하로 인해 서비스가 느려지거나
sentinel , replication 같은 구성에서 ping check에 영향이 갈 수도 있습니다.
그렇다고 client-output-buffer-limit 설정을 안하거나
client-output-buffer-limit slave 0 0 0 으로 설정하는 게 안전할까요?
이렇게 설정하게 되면 Master에 데이터가 몰려 redis server가 터지는 경우 slave도 바로 터져버리게 되기 때문에 오히려 HA 구성의 이점을 전혀 이용할 수 없게 됩니다.
그래서 아래와 같은 redis-benchmark 스크립트를 돌려가며 적절한 client-output-buffer-limit 값을 찾는게 중요합니다.
$ /usr/local/bin/redis-benchmark -h 10.111.111.111 -t set -d 2000000 -c 3000 -q -l -r 10000000000
참고로 AWS의 elasticache의 경우 인스턴스 타입마다 다르지만 maxmemory의 1/10 을 client-output-buffer-limit으로 설정한 모습입니다.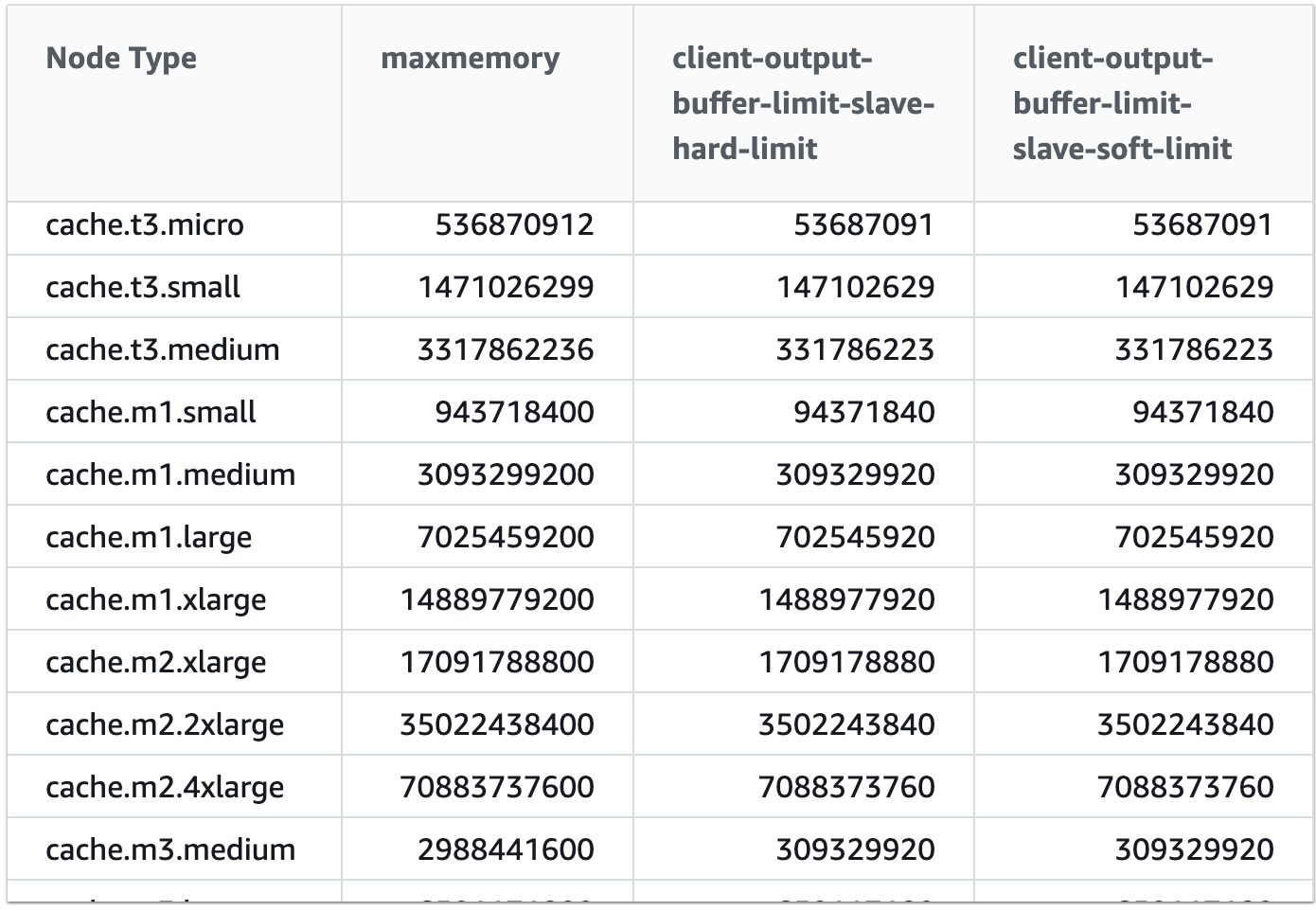
그래서 아래와 같이 정리할 수 있습니다.
* client-output-buffer-limit 설정을 maxmemory와 서비스 사용량 고려 없이 default로 사용하는 경우 이 값에 따라서 커넥션이 끊어질 수 있다
* Master - Slave 커넥션이 너무 빈번하게 끊어지면 마스터에 부하가 가고 서비스에 장애가 생길 수 있다.
* maxmemory 나 서비스 사용량등을 고려하여 이 값을 증가시키는 것이 좋다.
* 간단하게는 maxmemory의 1/10 정도로 설정하면 된다