지난 글에서 Redis와 Memcached 의 가장 큰 차이점으로 데이터를 저장할 수 있다는 점을 들며
RDB, AOF에 대한 내용을 다뤘었는데요
이번 글에서는 또 다른 차이점인 Redis의 다양한 자료구조에 대해 다뤄보겠습니다.
Redis Data Structures
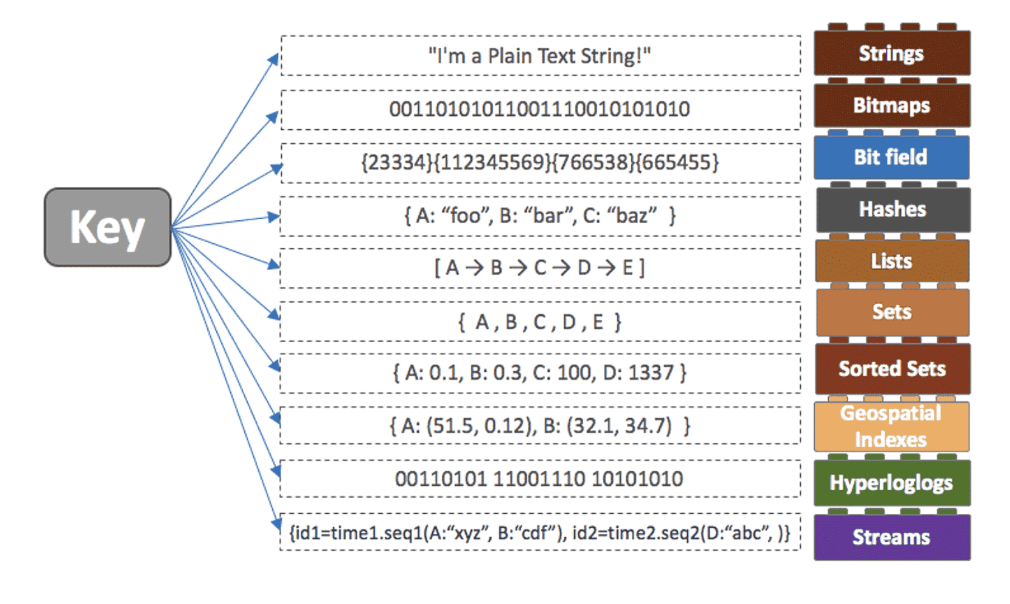
초기에는 String, Bitmap, Hash, List, Set, Sorted Set 정도의 데이터 타입만 제공하다가
버전이 올라가면서 현재는 Geospatial Index, Hyperloglog, Stream 까지 지원하고 있습니다.
이렇게 다양한 자료구조를 key-value 형태로 지원하는 점 뿐만 아니라
각 자료구조를 효율적으로 사용할 수 있도록 도와주는 커맨드를 지원하는 덕분에 개발의 편의성과 효율성을 높일 수 있는 것이 큰 장점입니다.
String
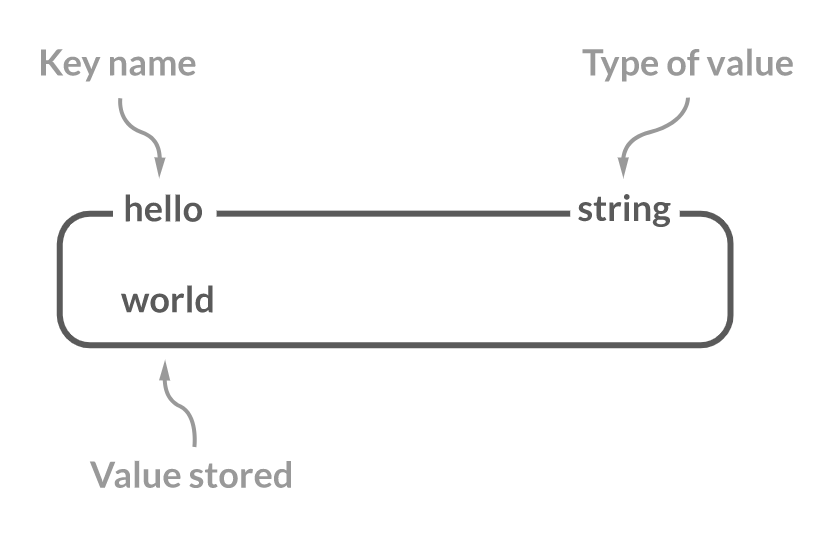
일반적인 Key-Value 의 data type 으로 이진 데이터 뿐만 아니라 모든 종류의 문자열 저장할 수 있습니다.
다양한 커맨드를 지원하여 문자열의 범위 검색이나 value를 정수형으로 변환하여 증감 연산도 가능합니다.
최대 저장 가능 크기는 512MB 입니다.
- set [key] [value] / get [key]
127.0.0.1:6001> set test string
OK
127.0.0.1:6001> get test
"string"
=> key-value 를 설정하고 조회하는 커맨드
- getset [key] [value]
127.0.0.1:6001> getset test "new string"
"string"
127.0.0.1:6001> get test
"new string"
=> key에 새로운 value를 setting 하기 이전에 이전 값을 보여주고 set 처리하는 커맨드
- incr [key] / incrby [key] <증가값>
127.0.0.1:6001> set num_test 1
OK
127.0.0.1:6001> incr num_test
(integer) 2
127.0.0.1:6001> incr num_test
(integer) 3
127.0.0.1:6001> incrby num_test 100
(integer) 103
- string value에 incr 하면?
127.0.0.1:6001> get test
"new string"
127.0.0.1:6001> incr test 1
(error) ERR wrong number of arguments for 'incr' command
- getrange [key] start end
127.0.0.1:6001> getrange test 0 2
"new"
127.0.0.1:6001> getrange test 0 -1
"new string"
=> string 범위 검색
Set
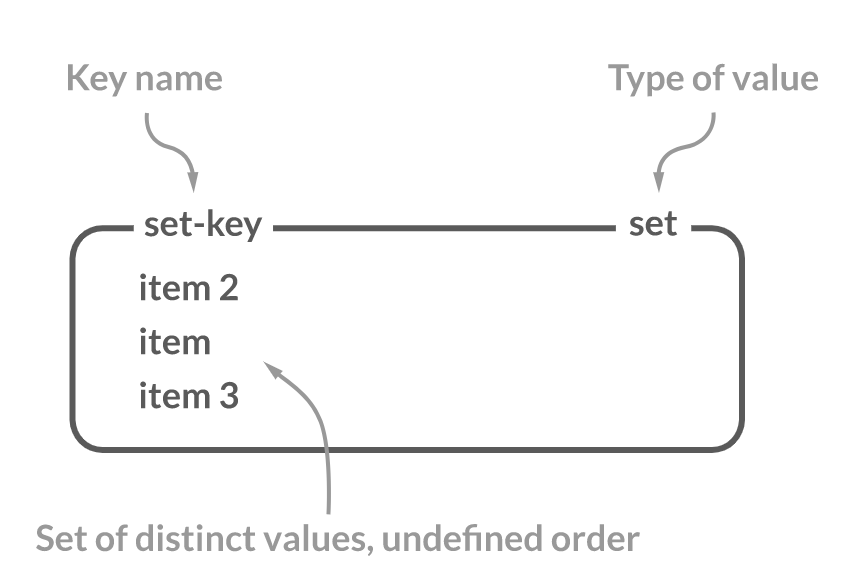
집합형 data type으로 정렬되지 않고 중복되지 않는 데이터를 저장합니다.
value를 추가하거나 지우는 작업을 처리할 땐 현재 set에 포함된 데이터 수와는 관계없이 O(1) 로 처리가 가능하며
집합형이기 때문에 합집합,교집합,차집합 같은 연산도 가능합니다.
- SADD [key] [member] / SMEMBBERS [key]
127.0.0.1:6001> SADD set_test 'test1'
(integer) 1
127.0.0.1:6001> SADD set_test 'test2'
(integer) 1
127.0.0.1:6001> SADD set_test 'test3'
(integer) 1
127.0.0.1:6001> SADD set_test 'test3'
(integer) 0
127.0.0.1:6001> SADD set_test 'test3'
(integer) 0
127.0.0.1:6001> SMEMBERS set_test
1) "test3"
2) "test2"
3) "test1"
=>SADD는 key에 member (value)를 추가하는 커맨드로 중복값은 허용하지 않습니다. SMEMBERS 는 key에 속한 member (value)를 보여주는 커맨드로 정렬이 되지 않습니다.
- 집합연산 SDIFF [key1] [key2] / SINTER / SUNION
127.0.0.1:6001> smembers set_test
1) "test3"
2) "test2"
3) "test1"
127.0.0.1:6001> smembers set_test2
1) "test_1"
2) "test3"
3) "test_3"
4) "test_2"
127.0.0.1:6001> SDIFF set_test set_test2
1) "test1"
2) "test2"
=> 차집합 연산
127.0.0.1:6001> SINTER set_test set_test2
1) "test3"
=> 교집합
127.0.0.1:6001> SUNION set_test set_test2
1) "test_2"
2) "test3"
3) "test2"
4) "test1"
5) "test_1"
6) "test_3"
=> 합집합
- SCARD [key]
127.0.0.1:6001> SCARD set_test
(integer) 3
=> key의 member (value) 개 수
- SSCAN [KEY] [MATCH pattern] [COUNT count]
127.0.0.1:6001> sscan myset 0
1) "5"
2) 1) "A2"
2) "A1"
.
.
9) "D2"
10) "D1"
127.0.0.1:6001> sscan myset 5
1) "0"
2) 1) "E1"
2) "B2"
3) "C1"
4) "B3"
5) "A3"
127.0.0.1:6001> sscan myset 0 MATCH A*
1) "5"
2) 1) "A2"
2) "A1"
127.0.0.1:6001> sscan myset 5 MATCH A*
1) "0"
2) 1) "A3"
=> 한번에 전체 member 를 조회하는 smembers 와 달리 SSCAN를 통해 일정단위로 조회 가능합니다.
위 예제처럼 MATCH 옵션으로 A로 시작하는 member만 조회할 수도 있습니다.
Sorted Set
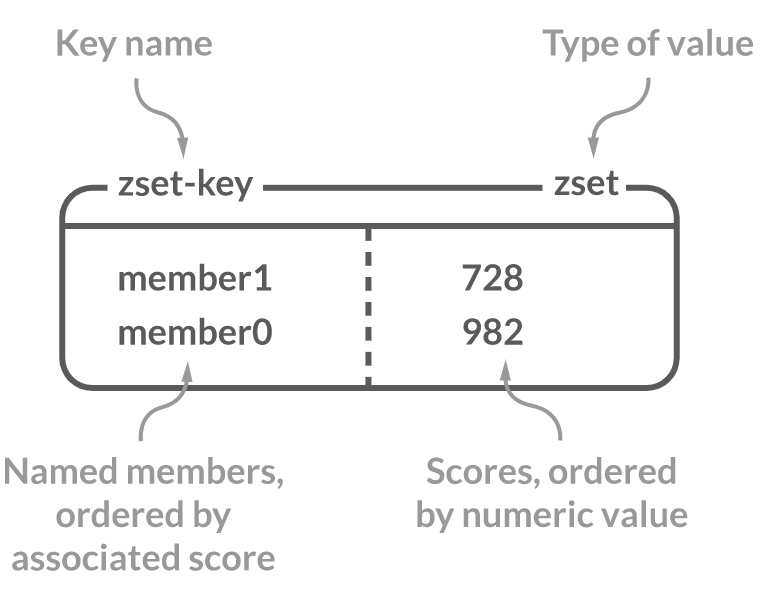
set data type에 정렬의 개념을 추가한 data type 입니다.
key의 각 member에 score를 매핑하여 score 오름차순으로 정렬할 수 있는 data type입니다.
정렬
- ZADD [key] [member]
127.0.0.1:6001> ZADD MID 1 fizz
(integer) 1
127.0.0.1:6001> ZADD MID 2 ryze
(integer) 1
127.0.0.1:6001> ZADD MID 3 garen
(integer) 1
127.0.0.1:6001> ZADD MID 1000 TF
(integer) 1
- ZRANGE [key]
127.0.0.1:6001> ZRANGE MID 0 -1
1) "fizz"
2) "ryze"
3) "garen"
4) "TF"
127.0.0.1:6001> ZRANGE MID 1 2
1) "ryze"
2) "garen"
=> score 순으로 정렬된 member 들 중 start ~ end 순서의 member를 조회 (start는 0부터 시작 )
- ZRANGEBYSCORE [key]
127.0.0.1:6001> ZRANGEBYSCORE MID 100 1000
1) "TF"
127.0.0.1:6001> ZRANGEBYSCORE MID 1000 +inf
1) "TF"
=> 특정 score 내의 member만 조회하는 커맨드 (+inf는 범위 끝까지)
- ZINCRBY [key] <증가값> [member]
127.0.0.1:6001> ZINCRBY MID 100 fizz
"101"
127.0.0.1:6001> ZRANGE MID 0 -1
1) "ryze"
2) "garen"
3) "fizz"
4) "TF"
=> score 증감연산도 가능
- ZSCAN [KEY] [MATCH pattern] [COUNT count]
127.0.0.1:6001> ZSCAN myzip 0 MATCH A*
1) "0"
2) 1) "A1"
2) "1"
3) "A2"
4) "2"
5) "A3"
6) "3"
=> sorted set의 member와 그의 score를 일정단위로 조회하는 기능
MATCH 옵션으로 특정 member만 조회할 수 있음
List
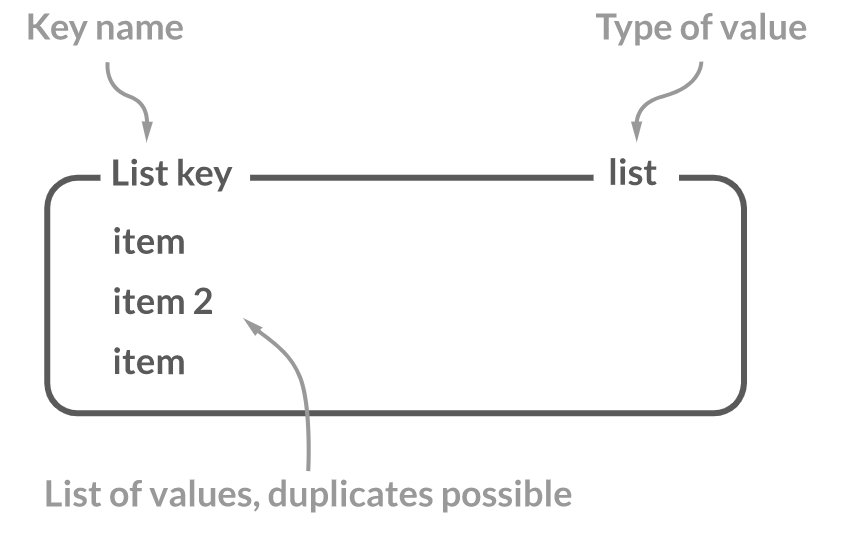
Set data type이 group 형태에 중복값을 가질 수 없는 data type이라면 List data type은 Array 형태로 key 하나에 n개의 값을 가지며 중복값도 가질 수 있는 data type 입니다.
일반적인 Linked list 라서 LPUSH , RPUSH 같은 list의 끝에 데이터를 추가할 때 O(1) 로 처리가능합니다.
- LPUSH / RPUSH [key] [value]
127.0.0.1:6001> LPUSH DB mysql
(integer) 1
127.0.0.1:6001> LPUSH DB oracle
(integer) 2
127.0.0.1:6001> RPUSH DB redis
(integer) 3
127.0.0.1:6001> LPUSH DB mongodb
(integer) 4
127.0.0.1:6001> LRANGE DB 0 10
1) "mongodb"
2) "oracle"
3) "mysql"
4) "redis"
- LPUSHX
127.0.0.1:6001> LPUSHX DB_2 mysql
(integer) 0
=> LPUSHX / RPUSHX 는 존재하는 KEY에만 PUSH 작업이 가능합니다.
DB_2 라는 key 를 기존에 생성하지 않았기 때문에 위 작업은 실패합니다.
- BLPOP / BRPOP [key]
========= A session =========
127.0.0.1:6001> BLPOP DB 10
1) "DB"
2) "oracle"
127.0.0.1:6001> BLPOP DB 10
1) "DB"
2) "mysql"
127.0.0.1:6001> BLPOP DB 0
========= B session =========
127.0.0.1:6001> LPUSH DB redis
(integer) 1
========= A session =========
1) "DB"
2) "redis"
(35.38s)
=> KEY에서 LPOP / RPOP 을 수행하는데 데이터가 없으면 timeout 만큼 기다려라 는 커맨드입니다.
그래서 KEY 에 데이터가 있으면 timeout값이 있어도 바로 LPOP, 즉 왼쪽에서 POP 하는 커맨드와 동일합니다.
그러나 KEY에 데이터가 없을 때 timeout 0으로 BLPOP 커맨드를 수행하면 데이터가 들어올때까지 기다렸다가
다른 세션(위에선 B session)에서 데이터가 들어오면 그때서야 LPOP 커맨드를 수행하게 됩니다.
Hash
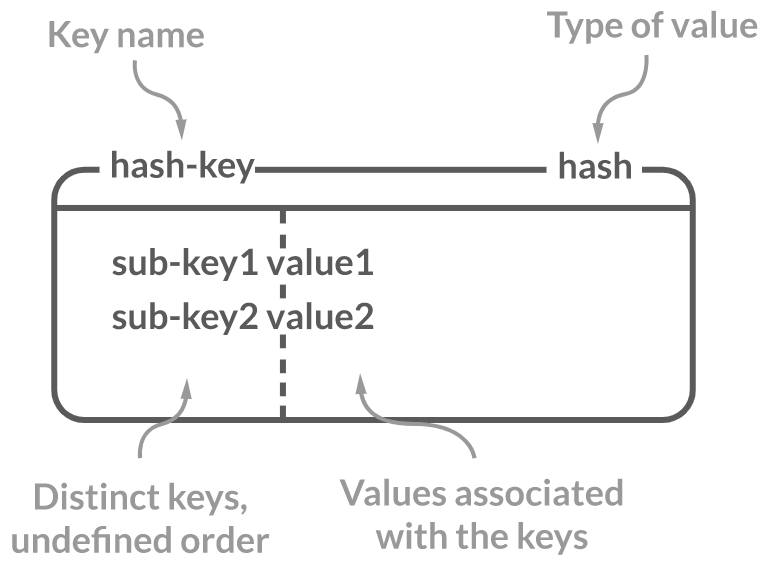
key 하나에 여러개의 field와 value 로 구성되는 data type으로 RDBMS의 테이블과 비슷한 개념입니다.
Hash key는 RDBMS 테이블의 PK, field 는 column, values는 value 로 매핑됩니다.
또한 Hash key가 PK의 역할을 하기 때문에 key 하나는 RDBMS에서 테이블의 한 row라고 할 수 있습니다.
- HSET [key] [field] [value]
127.0.0.1:6001> HSET mysql RDBMS yes
(integer) 1
127.0.0.1:6001> HSET mysql ENGINE innodb
(integer) 1
127.0.0.1:6001> HSET mysql REPLICATION yes
(integer) 1
=> 하나의 key에 여러개의 field와 value 를 저장할 수 있음
- HGET [key] [field] / HGETALL [key]
127.0.0.1:6001> HGET mysql RDBMS
"yes"
127.0.0.1:6001> HGETALL mysql
1) "RDBMS"
2) "yes"
3) "ENGINE"
4) "innodb"
5) "REPLICATION"
6) "yes"
=> key의 field 별로 조회 가능
- HDEL [key] [field]
127.0.0.1:6001> HDEL mysql RDBMS
(integer) 1
127.0.0.1:6001> HKEYS mysql
1) "ENGINE"
2) "REPLICATION"
127.0.0.1:6001> HVALS mysql
1) "innodb"
2) "yes"
- HSCAN [key] [MATCH pattern] [COUNT count]
127.0.0.1:6001> HSCAN myhash 0 MATCH *1
1) "0"
2) 1) "f1"
2) "v1"
=> hash의 field와 value를 일정단위로 조회하는 기능